[논문 리뷰] CITADEL: Conditional Token Interaction via Dynamic Lexical Routing for Efficient and Effective Multi-Vector Retrieval
![[논문 리뷰] CITADEL: Conditional Token Interaction via Dynamic Lexical Routing for Efficient and Effective Multi-Vector Retrieval](https://images.unsplash.com/photo-1592052416716-9541d5700ad0?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDE1fHxjfGVufDB8fHx8MTcyMzExMDUyNXww&ixlib=rb-4.0.3&q=80&w=960)
이번 시간에는 “CITADEL: Conditional Token Interaction via Dynamic Lexical Routing for Efficient and Effective Multi-Vector Retrieval” 논문을 살펴봅니다.
최근 sparse (e.g., BM25) 와 dense (e.g., DPR) retriever의 장점을 결합한 Multi-vector retriever method가 다양한 검색 태스크에서 좋은 성능을 보여주고 있습니다. 하지만 이러한 방법은 Single-vector retriever 방법에 비해 훨씬 느리고 인덱스를 저장하는데 많은 공간이 필요하다는 단점이 있습니다.
따라서 연구팀은 CITADEL이라는 모델을 제안하여 위 문제를 극복하고자 했습니다. 위 문제들을 어떻게 해결할 수 있었을까요? 논문은 링크에서 확인할 수 있습니다 😊
관련하여 COIL 논문 리뷰와 XTR 논문 리뷰를 읽어보시는 것도 큰 도움이 됩니다!
Abstract
- sparse와 dense retriever의 장점을 결합한 multi-vector method는 좋은 성능을 보여주나, single-vector method에 비해 느리고, 인덱스를 저장하는데 많은 저장 공간이 필요함
- 따라서 연구팀은 dynamic lexical routing을 통해 conditional token interaction을 수행하는 CITADEL을 제안
- CITADEL은 서로 다른 토큰 벡터를 예측된 lexical key로 라우팅하여, query token 벡터가 동일한 key로 라우팅 된 document 토큰 벡터와만 interaction하도록 학습됨.
- CITADEL은 ColBERT-v2와 비교하여 동일하거나 더 나은 성능을 달성하면서도, 거의 40배 빠른 속도를 보여줌
Introduction
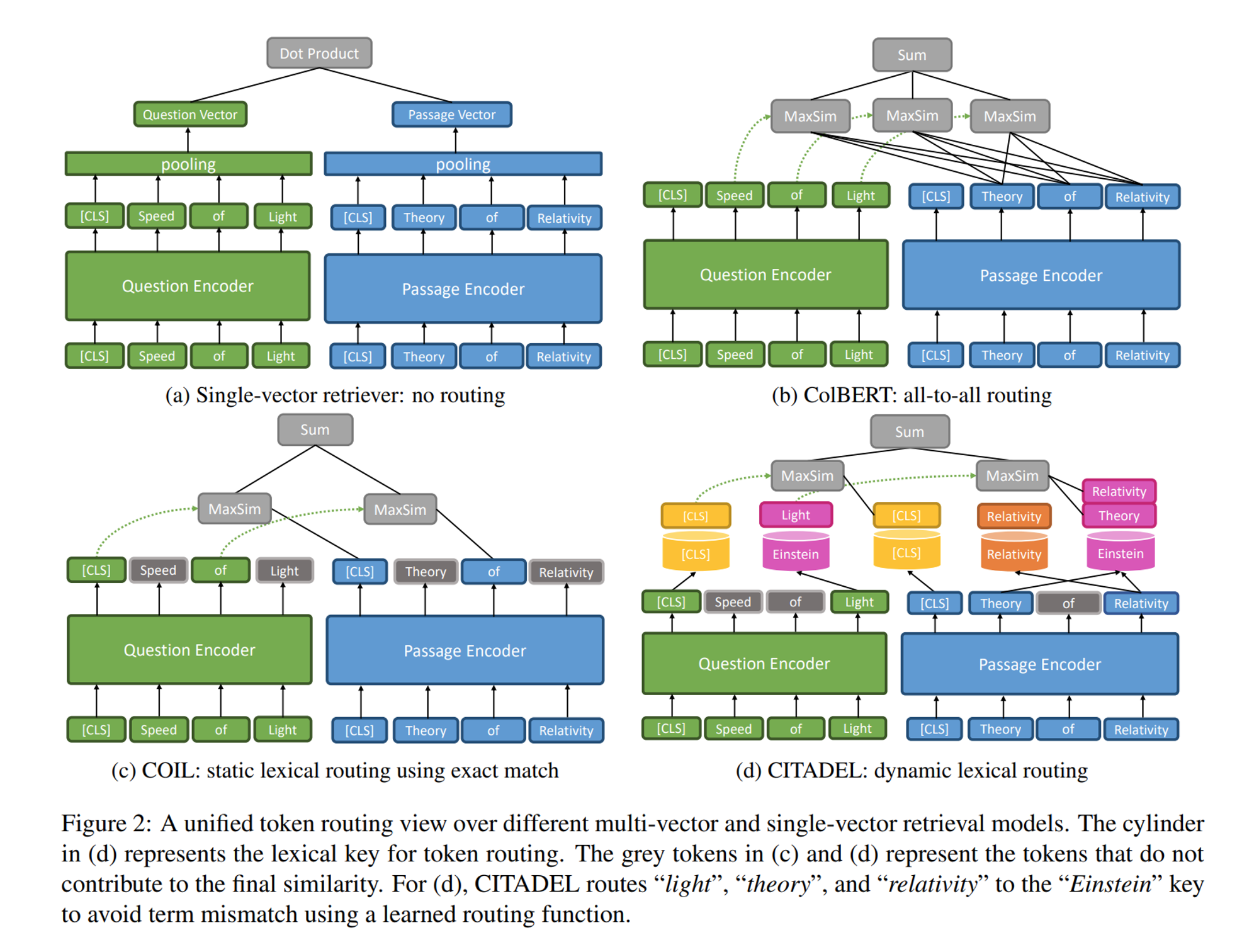
본격적으로 CITADEL에 대해 알아보기 전에, dense retriever의 발전 역사를 간략하게 살펴보겠습니다.
(a) Question과 Passage vector를 비교하는 Single-vector retriever (e.g., DPR)은 sparse retriever의 문제점으로 꼽히는 term mismatch problem을 해결하였으나, entity-heavy question 또는 out-of-domain 데이터셋에서 약한 모습을 보여주었습니다.
(b) 따라서 Multi-vector retriever (e.g., ColBERT)는 token-level interaction을 통해 앞서 지적한 entity-heavy question 또는 out-of-domain에서도 좋은 성능을 보입니다. 하지만 token-level interaction으로 인한 index 크기와 높은 latency가 문제점으로 지적되었습니다.
(c) 앞서 높은 latency 문제를 극복하고자 COIL에서는 exact match constraint를 통해 동일한 token id에 대해서만 interaction를 수행함으로써 latency 문제를 극복할 수 있었습니다. 하지만 token id가 동일해야만 interation을 수행할 수 있어, word mismatch problem이 발생할 수 있습니다.
위 내용을 정리하면 연구팀이 풀어야 할 문제는 다음과 같이 정리할 수 있습니다.
- 최근에는 token-level interaction을 통해 검색 성능을 높이는 추세이다. (ColBERT)
- 하지만 모든 token을 interaction을 수행하는 것은 높은 latency가 발생한다.
- 동일한 token-id에 대해서만 exact match하여 interaction을 하는 것은 latency는 줄일 수 있으나 word mismatch problem이 발생할 수 있다. (COIL)
The CITADEL Method
그렇다면 위 문제점들을 어떻게 극복할 수 있을까요?
연구팀은 기존 방식처럼 all-to-all routing (e.g., ColBERT) 또는 inflexible heuristics-based static routing (e.g., COIL)이 아닌 dynamic lexical routing을 제안합니다.
dynamic lexical routing은 interaction할 query와 passage token을 모델이 dynamic하게 선택하도록 하는 방법입니다. 구체적인 동작 방식을 이어서 살펴보겠습니다!
Dynamic Lexical Routing
우선 query와 passage의 각 contextualized token embedding \( (v_{q_i}, v_{d_j}) \)가 주어지면, token level router representation인 \( w_{q_i} = φ(v_{q_i}) \)와 \( w_{d_j} = φ(v_{d_j}) \)를 구합니다.
그리고 router representation들을 내림차 순으로 정렬하고, 상위 K개의 query key와 상위 L개의 document key를 선택합니다.
예를 들어 query token \( q_i \)에 대해 선택된 key는 \( \{E_{qi}^{(1)}, E_{qi}^{(2)}, \cdots, E_{qi}^{(K)}\} \) 가 되고, document token \( d_j \) 에 대해 선택된 key는 \( \{E_{dj}^{(1)}, E_{dj}^{(2)}, \cdots, E_{dj}^{(L)}\} \) 가 됩니다.
그리고 query token과 document token에 대해 예측된 routing 가중치는 각각 다음과 같습니다.
\[ \{w_{qi}^{(1)}, w_{qi}^{(2)}, \cdots, w_{qi}^{(K)}\} \]
\[ \{w_{dj}^{(1)}, w_{dj}^{(2)}, \cdots, w_{dj}^{(K)}\} \]
이제 위 값들을 이용하여 최종 similiarity score를 계산합니다. 여기서 \( \varepsilon_i^{(k)} \)는 router가 예측한 dynamic key의 집합을 의미합니다. \( \varepsilon_i^{(k)} = \{ j,l | E_{d_j}^{(l)} = E_{q_i}^{(k)}, 1 \leq j \leq M, 1 \leq l \leq L \} \)
\[ s(q, d) = \sum_{i=1}^{N} \sum_{k=1}^{K} \max_{j,l \in \varepsilon_i^{(k)}} (w_{qi}^{(k)} \cdot v_{qi})^T (w_{dj}^{(l)} \cdot v_{dj}) \]
모델의 학습은 DPR에서 사용되는 constrastive learning을 활용했습니다.
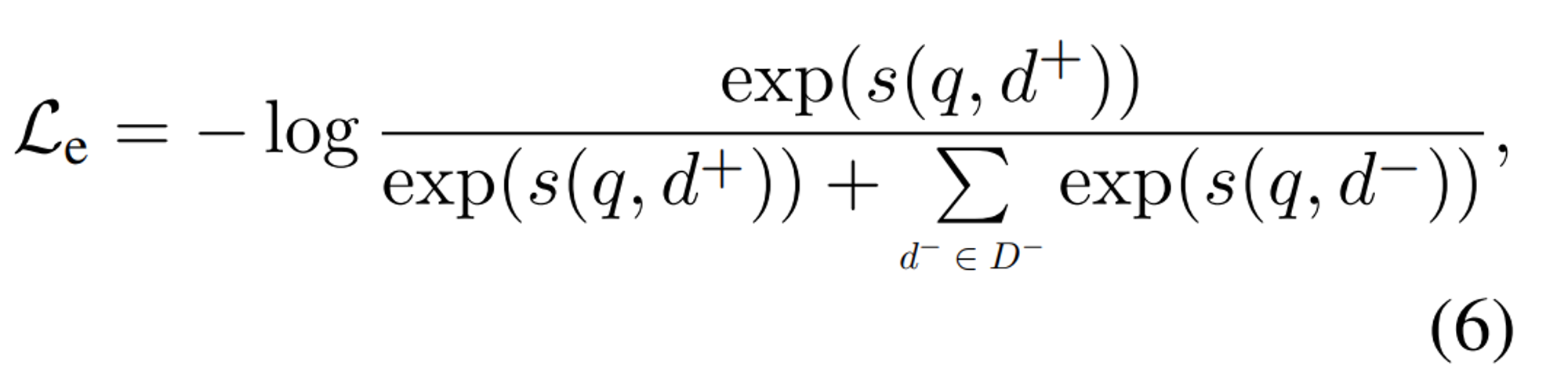
Router Optimization
위에서 사용한 router는 어떻게 학습시킬 수 있었을까요?
연구팀은 router를 학습시킬 때 constrastive loss를 활용하였습니다. 이는 query와 document간 overlapped 되는 key가 positive \( (q,d^{+}) \) pair에서 많도록 하고, negative \( (q,d^{-}) \) pair에서는 적도록 합니다.
token level router representations가 주어졌을 때 sequence level representation은 다음과 같이 정의됩니다. 이때 Max Pooling이 다른 Pooling 기법과 비교했을 때 가장 효과적이었다고 합니다.
\[\Phi = \max_{j=1}^{M} \phi(v_j) \]
최종적으로 router를 학습시키기 위한 constrastive loss는 다음과 같습니다.
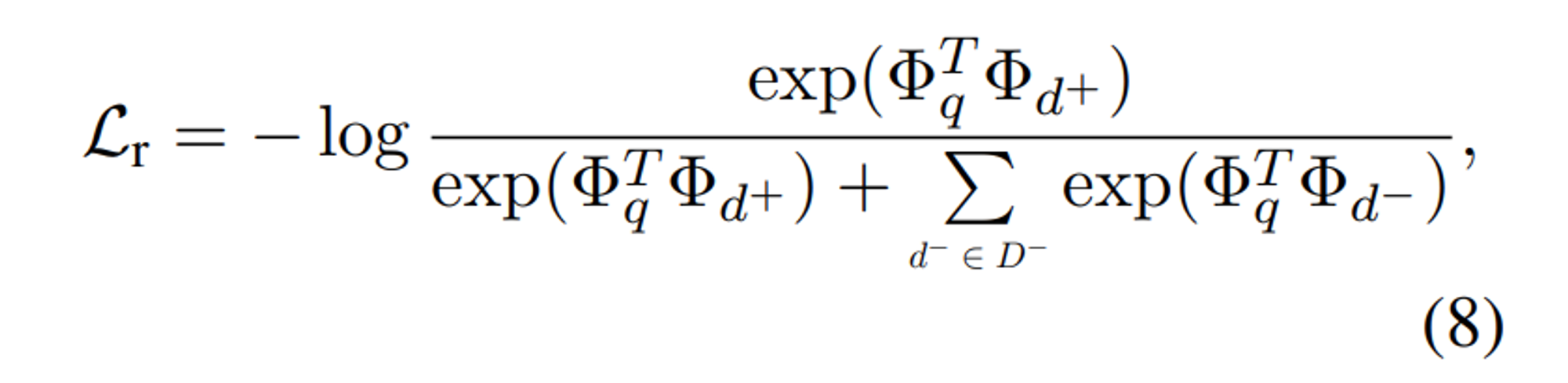
Sparsely Activated Router Design
연구팀은 Router에서 전통적으로 많이 사용하는 Softmax activation이 아닌 SPLADE에서 제안한 activation function을 사용했습니다.
그 이유로는 softmax function의 경우 많은 차원 (약 3만 개 이상)에서 작은 확률을 산출하는 경향이 있다고 합니다. 이때 두 확률의 곱은 더 작아지고 이로 인해 해당 gradient 값이 너무 작아져 routing weight를 계산하는데 적합하지 않다고 합니다.
따라서 SPADE에서 제안한 activation function을 사용하였고 수식은 아래와 같습니다.
\[ \phi(v_j) = \log(1 + \text{ReLU}(W^T v_j + b)) \]
위 function의 주요 특징은 다음과 같습니다.
- ReLU activation: 관련 없는 key를 필터링 할 수 있음
- Log-saturation: 지나치게 큰 “wacky(이상한)” 가중치를 억제할 수 있음
이를 통해 연구팀은 더 효율적이고 효과적으로 routing weight를 계산할 수 있었다고 합니다.
Regularization for Routing
이외에도 연구팀은 token routing을 효율적으로 하기 위해 다양한 기법들을 도입했는데요.
L1 regularization
각 토큰을 여러 키에 라우팅하면 인덱스 크기가 커진다는 문제점이 있다고 합니다.
따라서 연구팀은 L1 정규화를 통해 가장 의미 있는 토큰의 interation만 유지하도록 유도하였습니다.
이를 통해 더 많은 routing weight를 0으로 만들어 중요하지 않은 단어는 무시하여 인덱스 키를 줄이고 검색 효율성을 높이는데 기여했다고 합니다.
\[ L_s = \frac{1}{B} \sum_{i=1}^{B} \sum_{j=1}^{T} \sum_{k=1}^{|V|} \phi(v_{ij})^{(k)} \]
B = 배치크기, |V| = 키의 개수, T = 시퀀스의 길이
Load Balancing
기존 COIL 모델의 경우 static lexical routing을 하는 과정에서 공통 “Key”가 더 자주 활성화됩니다.
이는 큰 토큰 index를 더욱 자주 검색해야 하므로 latency가 증가할 수 밖에 없습니다.
따라서 연구팀은 각 토큰 임베딩을 다양한 key에 고르게 분배할 수 있도록 하여 latency를 줄이고자 하였습니다.
Switch Transformer에 영감을 받아 다음과 같은 load balancing loss 수식을 제안합니다.
\[ L_b = \sum_{k=1}^{|V|} f_k \cdot p_k \]
여기서 \( f_k \)는 토큰 임베딩이 k번째 키로 라우팅 될 확률의 배치 근사치이고, \( p_k \)는 k번째 키로 라우팅 된 토큰의 총 수의 배치 근사치를 의미합니다. 수식은 아래와 같습니다.
\[ p_k = \frac{1}{B} \sum_{i=1}^{B} \sum_{j=1}^{T} \frac{\exp(W_k^T v_{ij} + b_k)}{\sum_{k'} \exp(W_{k'}^T v_{ij} + b_{k'})} \]
\[ f_k = \frac{1}{B} \sum_{i=1}^{B} \sum_{j=1}^{T} I\{\argmax(p_{ij}) = k\} \]
\[ p_{ij} = softmax(W^T_{v_{ij}} + b ) \]
CITADEL 훈련에 필요한 최종적인 loss는 다음과 같습니다.
\[ L = L_e + L_r + \alpha \cdot L_b + \beta \cdot L_s \]
Inverted Index Retrieval
이제 토큰 임베딩을 lexical key에 따라 어떻게 저장하는지 살펴봅니다.
BM25와 유사하게 inverted index retrieval 방식을 사용합니다. 다만 각 token에 대해 scalar 대신 low-dimensional vector와 doc product를 사용한 term relevance를 저장합니다.
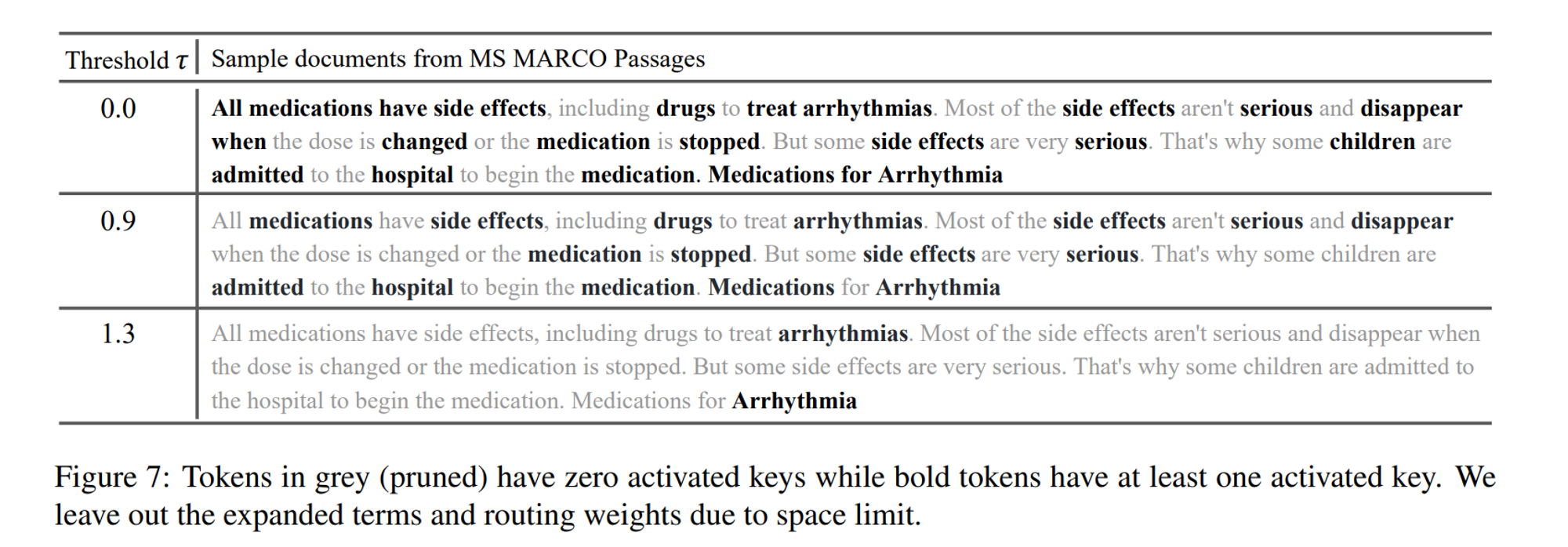
Indexing and Post-hoc Pruning
훈련 이후에는 특정 threshold \(\tau\) 이하의 routing weight를 가진 vector 들을 pruning 하여 index 저장 공간을 절약합니다.
Post-hoc Pruning을 통해 정확도 손실은 거의 없이 인덱스 크기를 3배 이상 줄일 수 있었다고 합니다.
그리고 lexicon (V)의 Key (E)에 대한 token index \( I_E \)는 모든 문서 (d)에 대한 token embedding (\(v_{d_j}\))와 routing weight (\(w^E_{d_j}\))로 구성하여 정의할 수 있습니다.
\[I_E = \{w^E_{d_j} \cdot v_{dj} | w^E_{d_j} > \tau, 1 \leq j \leq M, \forall d \in C\} \]최종 검색 인덱스는 다음과 같이 정의됩니다.
\[I = \{I_E | E \in V\}\]
여기서 앞서 살펴본 load balancing loss가 인덱스 크기 분포를 고르게 유지하도록 합니다.
그리고 document의 경우 최대 5개의 라우팅 키를, query의 경우 1개의 라우팅 키를 설정합니다.
document의 경우 query보다 더 많은 정보를 포함하고 있어 더 많은 키 용량이 필요해 더 많은 라우팅 키를 할당했습니다.
더불어 query에 대해 1개 이상의 라우팅 키를 사용하면 정확도는 향상되지 않는 반면 latency는 급격히 증가한다는 문제점이 있었다고 합니다.
Token Retrieval
마지막으로 CITADEL 모델이 어떻게 query를 처리하는지 살펴보겠습니다.
query 처리 과정은 다음과 같습니다.
- query encoding: 쿼리 (q)를 토큰 벡터 시퀀스 \(\{v_{qi}\}_{i=1}^{N}\)로 인코딩합니다.
- token routing: 각 벡터를 top-1 key E로 라우팅하고, 라우팅 가중치 \(W_{q_i}^E\)를 곱합니다.
- final representation \(W_{q_i}^E \cdot v_{qi}\)를 해당 토큰 인덱스 \(I_E\)로 보냅니다.
- 각 쿼리 토큰의 document ranking을 병합하여 최종 ranking 리스트를 생성합니다.
Experiments
CITADEL의 평가 결과에 대해 살펴보겠습니다.
MS MARCO Passages Retrieval
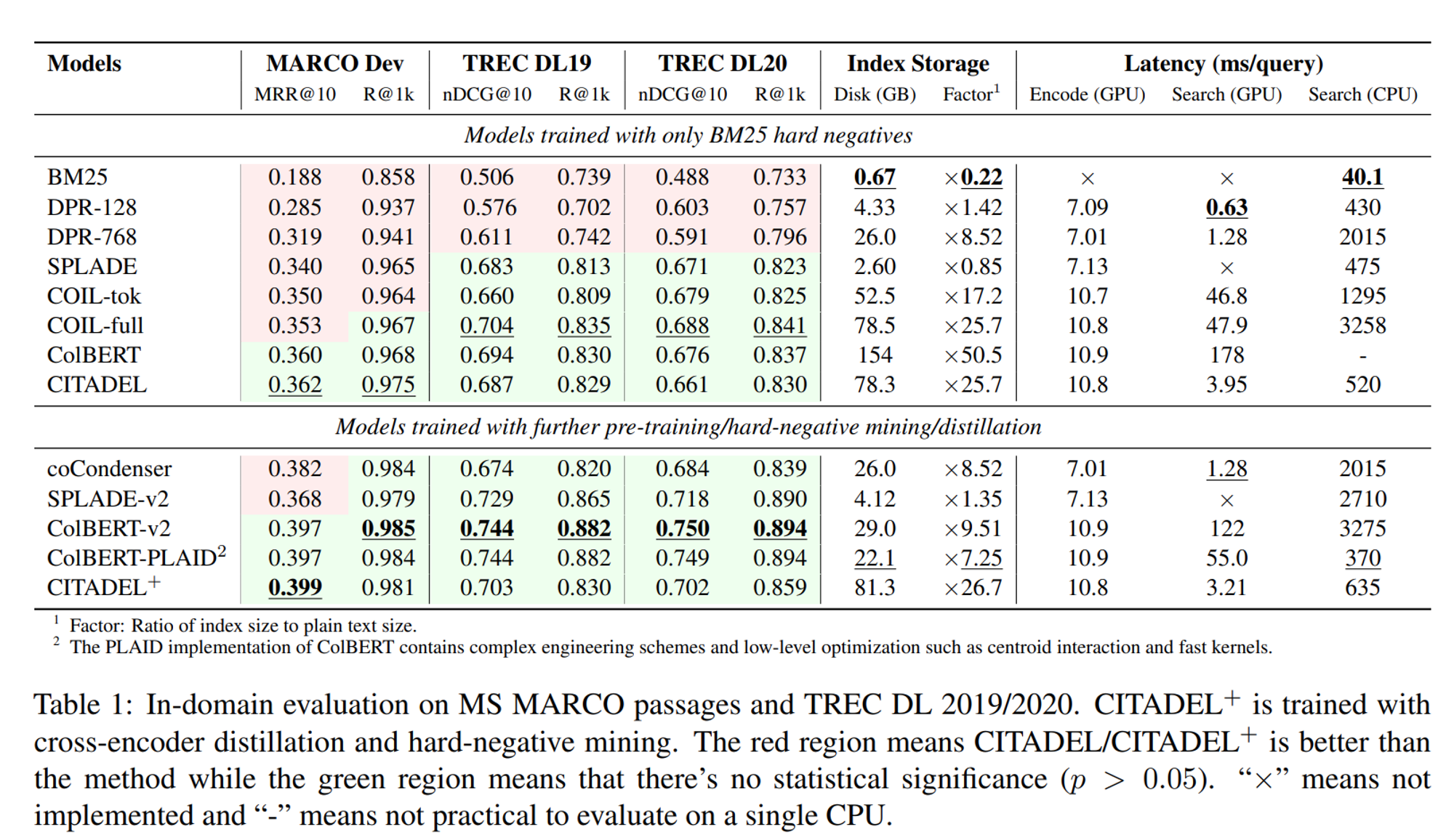
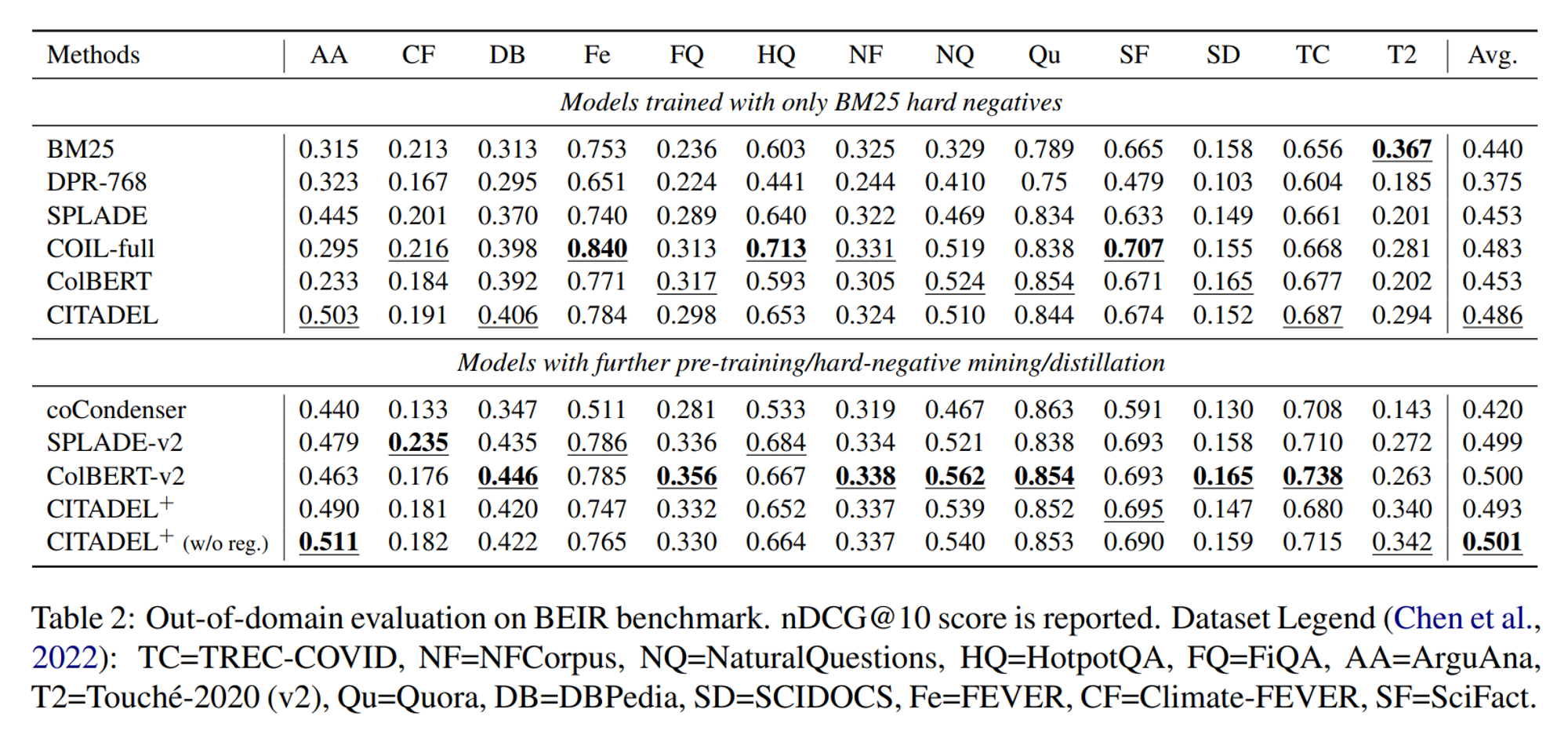
In-domain 성능은 MS MARCO와 TREC DL 2019 벤치마크를 바탕으로 평가되었습니다.
우선 Table 1을 살펴보면 MS-MARCO에서 CITADEL/CITADEL+은 모두 베이스라인 모델보다 높은 MRR 및 Recall 점수를 보여줌과 동시에 latency 또한 GPU 상에서 DPR-768과 비슷한 속도를 보이는 등 좋은 성능을 보여주고 있습니다.
TREC DL 2019/2020에서는 몇몇 베이스라인의 성능을 능가하지는 못했지만 t-test (p <0.05)에서 통계적으로 유의미한 차이가 없음을 검증했다고 합니다.
BEIR: Out-of-Domain Evaluation
이어 BEIR 벤치마크를 통해 평가된 Out-of-Domain 성능을 살펴보겠습니다.
마찬가지로 CITADEL과 CITADEL+ 모두 좋은 결과를 보여주고 있습니다.
흥미로운 점은 CITADEL+에서 load balancing과 L1 regularization 등을 적용하지 않았을 때 더 좋은 성능을 보였는데, 이는 정규화를 통한 token interaction 수를 줄이는 작업이 out-of-domain에서는 정확도가 떨어질 수 있다고 합니다.
Performance Anaysis
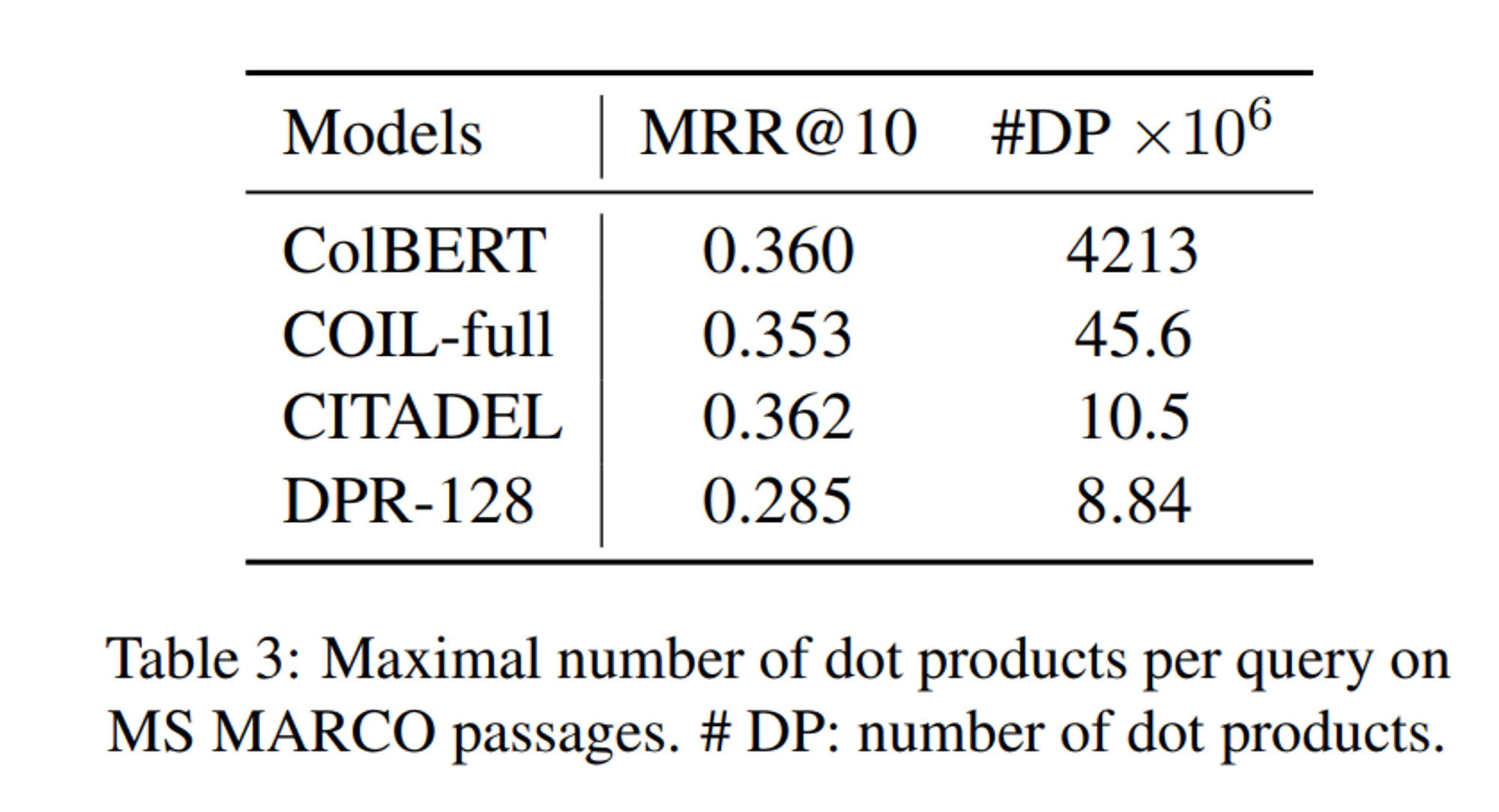
이외에도 MS MARCO passage에 대해 query 당 dot product의 수를 보면 CITADEL이 DPR-128과 유사한 dot product 횟수로 더욱 높은 MRR을 보이고 있음을 알 수 있습니다.
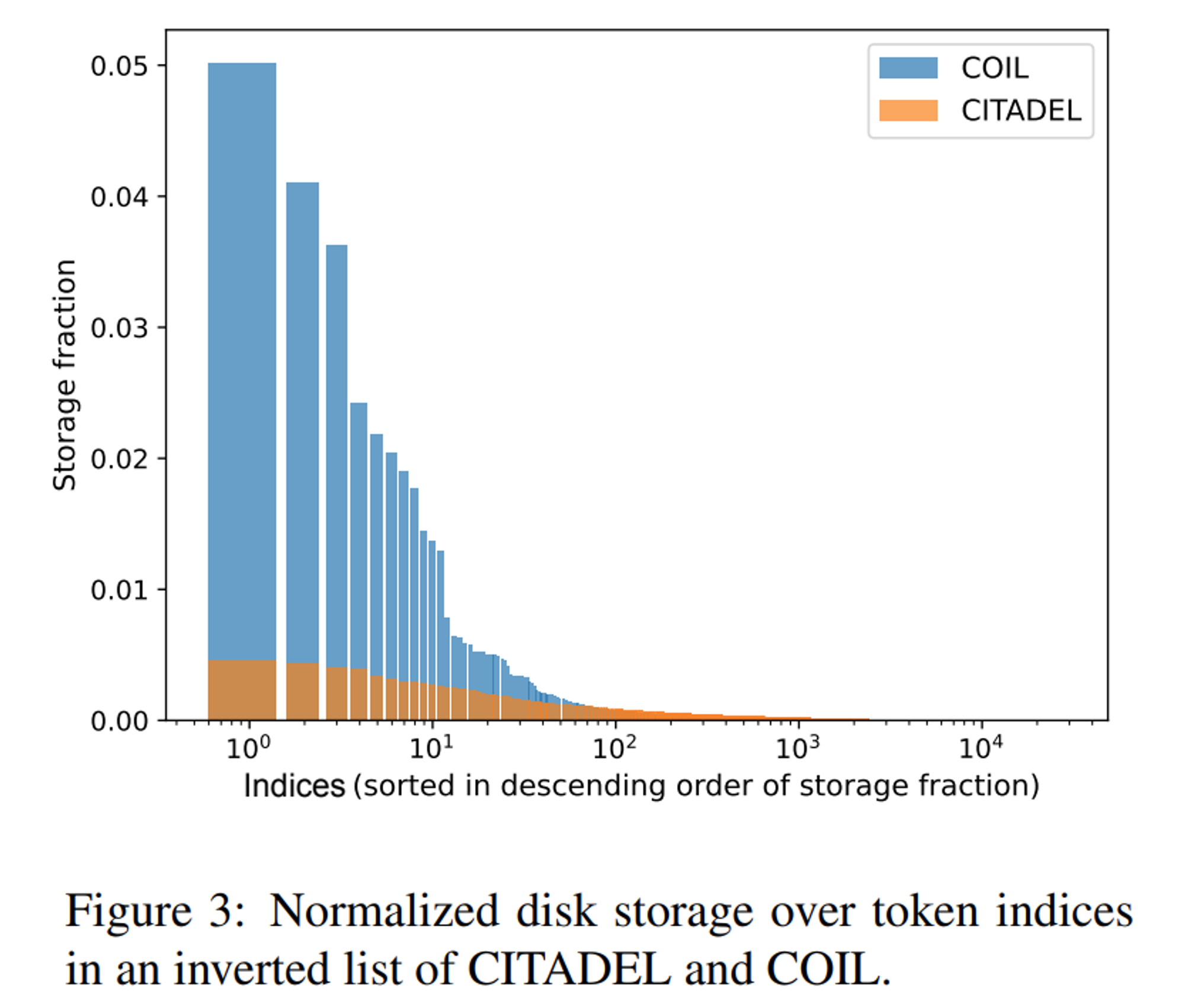
load balacing을 통한 balaced inverted index의 효과에 대해서도 살펴보겠습니다.
COIL의 경우에는 토큰 임베딩의 입력 ID를 키로 사용하는데, 이는 corpus의 토큰 분포에 의해 인덱스 분포가 결정된다고 합니다. 따라서 자주 사용되는 단어 (e.g., the, a)는 더 큰 인덱스 크기를 사용합니다.
반면에 CITADEL은 라우터 예측을 키로 사용하는데, 여기에 load balancing loss를 적용하여 균형 잡힌 index 분포를 유지할 수 있다고 합니다. 덕분에 CITADEL은 COIL보다 8배 작은 최대 인덱스 크기를 가지며, 검색 latency를 줄이는데 기여한다고 합니다.
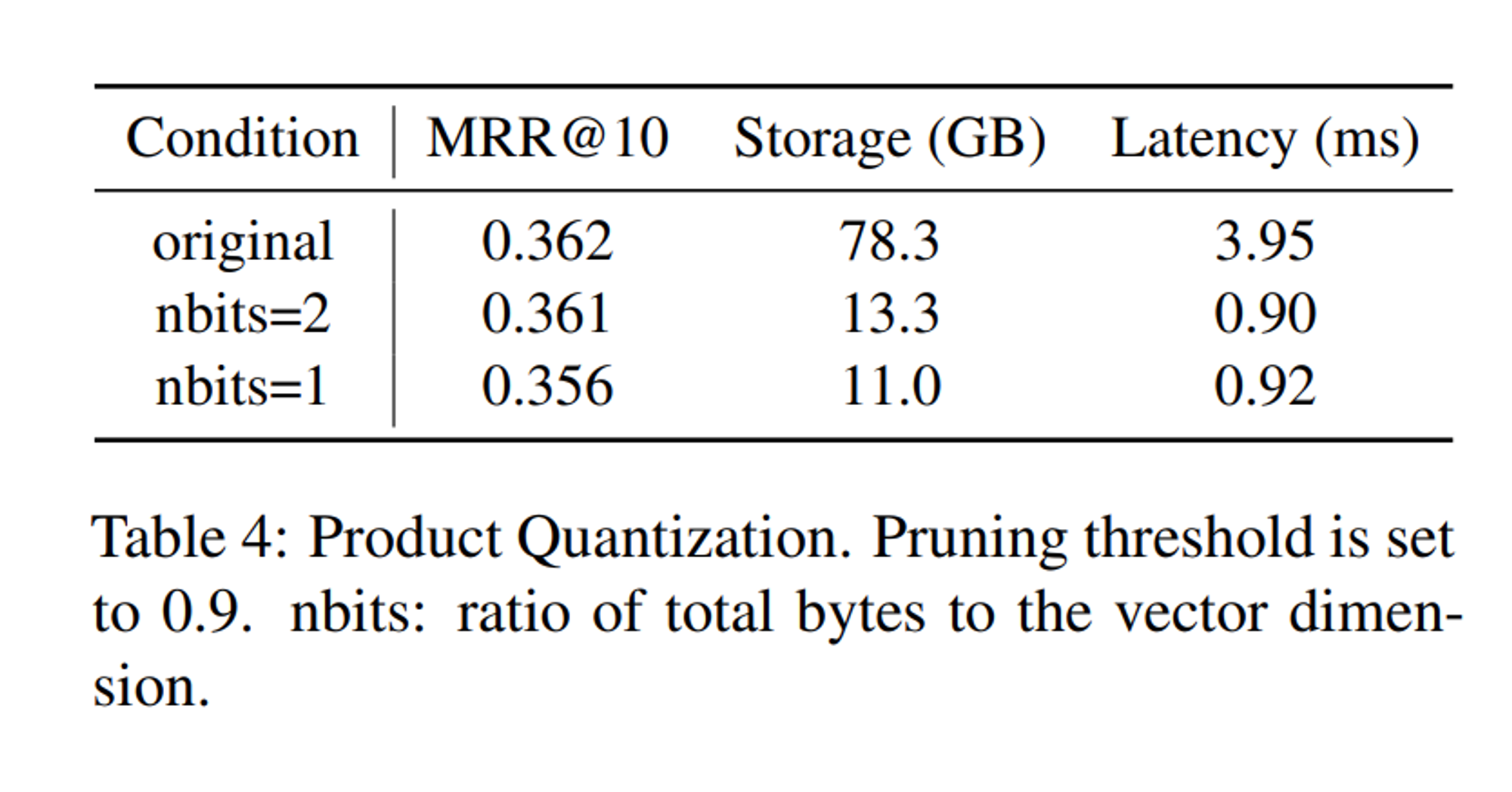
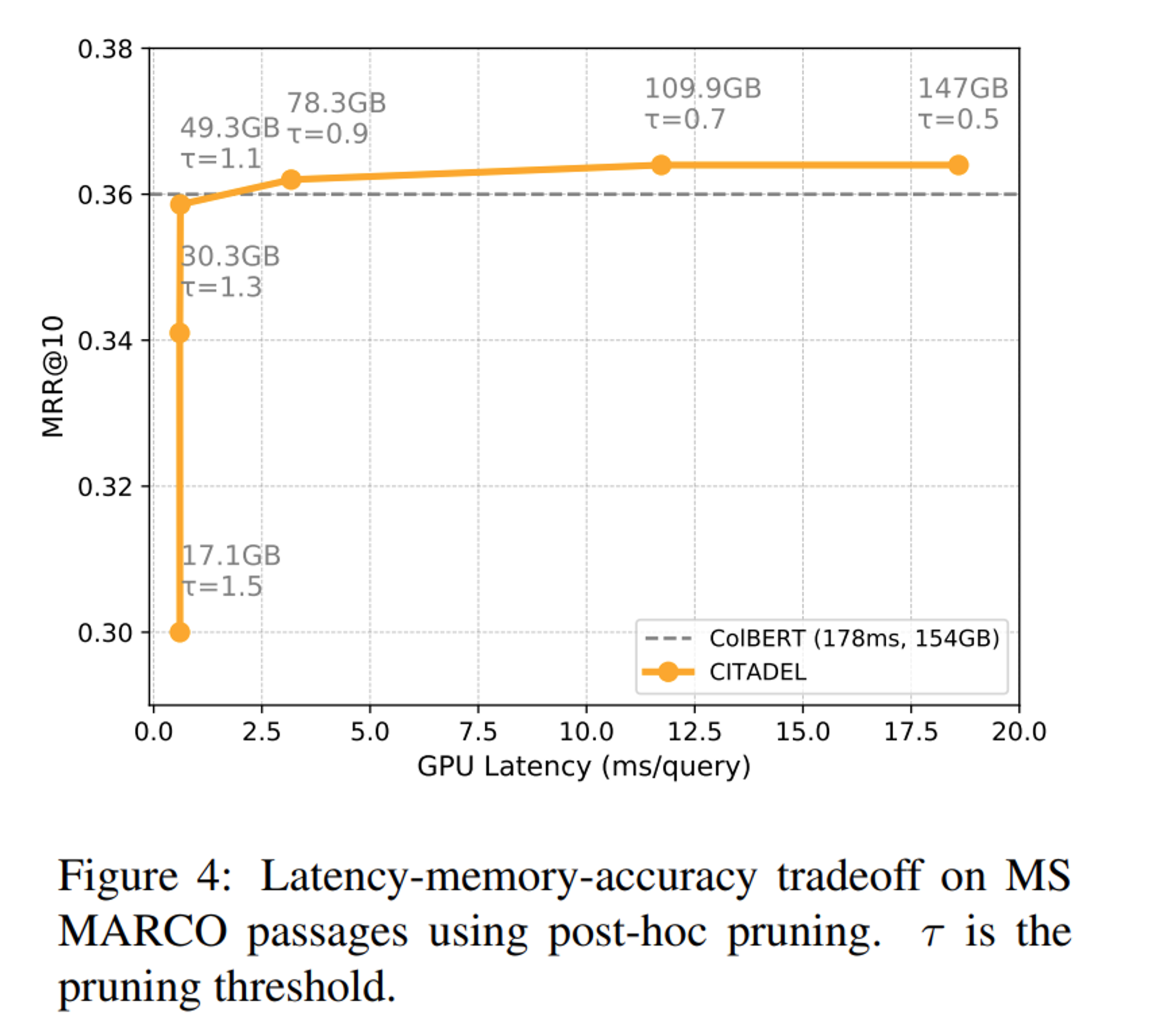
pruning 값 \( \tau \)에 대해서도, \( \tau \)=0.9~1.1일때 가장 효과적인 Latency-Memory-Accuracy Trade off를 보였다고 합니다. 더 나아가 Product Quantization을 통해 latency와 저장 공간을 추가로 절약할 수 있다고 합니다.
Ablation Study
연구팀은 다양한 조건에서의 ablation study도 진행했는데요. 간단하게 요약해서 살펴보겠습니다.
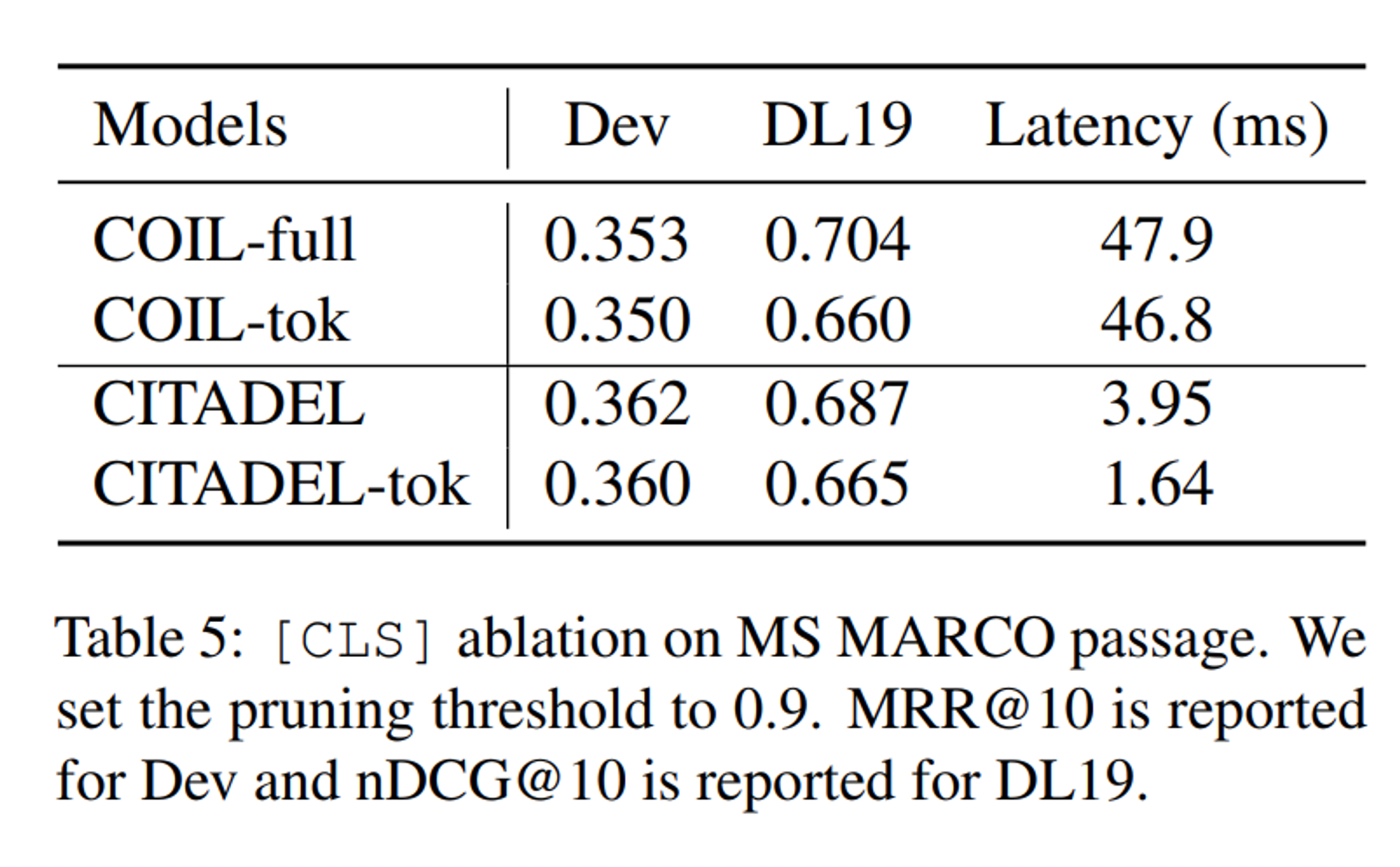
- Impact of [CLS]
- [CLS] 벡터를 제거하면 latency는 감소
- 그러나, 특히 TREC-19에서 in-domain 효과가 감소함
- 그럼에도 ITADEL-tok (w/o [CLS])는 여전히 COIL-tok보다 precision과 latency에서 더 우수함
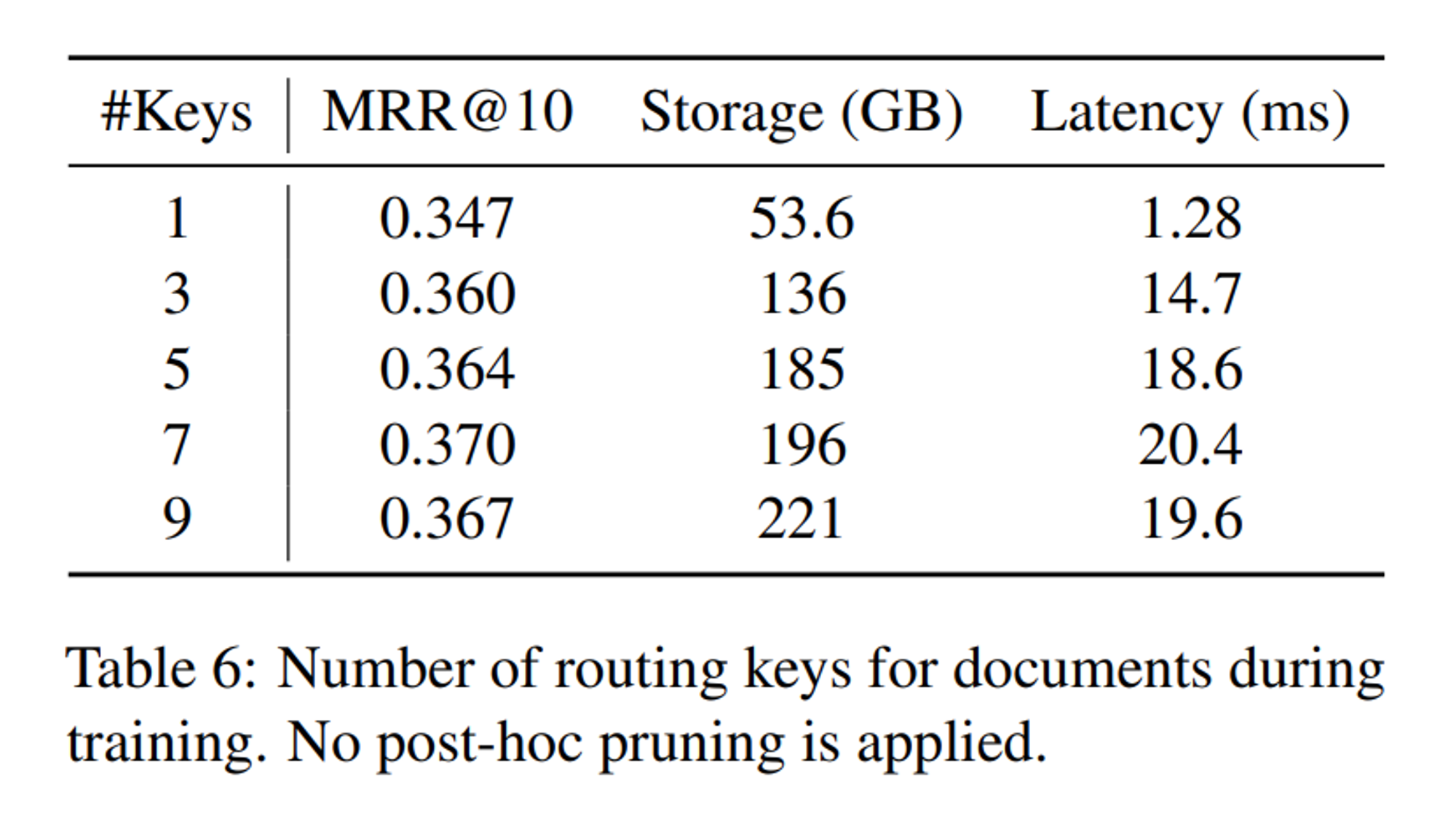
- Number of Routed Experts.
- 각 document token에서 훈련 및 추론 중에 최대 라우팅 키 개수를 변경하는 실험 진행
- 라우팅 키 개수가 증가함에 따라 인덱스 저장 공간도 급격히 증가하지만, MRR@10 score도 증가함. 하지만 7개 키 이상에서는 성능 향상이 정체됨.
- 라우팅 키가 3개 이상일 때는 latency도 크게 증가하지 않는데, 이는 load balancing loss의 효과일 수 있음.
Conclusion
- CITADEL이라는 새로운 multi-vector retrieval 방법 제안
- dynamic lexical routing을 통해 ColBERT의 all-to-all interaction의 중복성 문제를 줄이고, COIL의 word-mismatch problem도 완화함
- 여러 벤치마크 데이터셋에서 SOTA 성능을 달성함과 동시에 ColBERT-v2보다 40배, 가장 효율적인 multi-vector 검색 라이브러리인 PLAID보다 17배 빠름.
감사합니다 😁
![[논문 리뷰] ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS](https://images.unsplash.com/photo-1499428665502-503f6c608263?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDcyfHx8fHx8fHwxNzUyNDgwODc3fA&ixlib=rb-4.1.0&q=80&w=750)
![[논문 리뷰] Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning](https://images.unsplash.com/photo-1742325989789-b42912a531dd?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDN8fHx8fHx8fDE3NDI4ODc1Nzl8&ixlib=rb-4.0.3&q=80&w=750)
![[번역] The Bitter Lesson](https://images.unsplash.com/photo-1738300332814-225c81707b1b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDIxfHx8fHx8fHwxNzM5NjE5MjA1fA&ixlib=rb-4.0.3&q=80&w=750)
![[논문 리뷰] Evaluating Very Long-Term Conversational Memory of LLM Agents](https://images.unsplash.com/photo-1731332066050-47efac6e884f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDZ8fHx8fHx8fDE3MzIwMzU2MDB8&ixlib=rb-4.0.3&q=80&w=750)
![[논문 리뷰] Beyond Retrieval: Embracing Compressive Memory in Real-World Long-Term Conversations](https://images.unsplash.com/photo-1725992340772-47fd8f8df459?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDN8fHx8fHx8fDE3Mjg3MTkzNDZ8&ixlib=rb-4.0.3&q=80&w=750)
Member discussion