[논문 리뷰] Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
![[논문 리뷰] Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning](https://images.unsplash.com/photo-1742325989789-b42912a531dd?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDN8fHx8fHx8fDE3NDI4ODc1Nzl8&ixlib=rb-4.0.3&q=80&w=1200)
들어가며
이번 시간에는 LLM이 검색 엔진과 상호작용하며 추론(Reasoning)을 수행할 수 있는 강화 학습 프레임워크 Search-R1을 소개합니다. 최근 OpenAI의 Deep Research나 여러 최신 연구에서 알 수 있듯, LLM의 추론 능력뿐 아니라 실시간 검색과 결합된 Reasoning이 큰 주목을 받고 있습니다.
하지만 기존의 RAG(Retrieval-Augmented Generation)이나 Tool-Use 방식은
- 복잡한 다단계 검색에 유연하게 대응하기 어렵거나
- 대규모 고품질 지도 학습 데이터가 필요하다는 한계점이 있습니다.
이런 문제를 해결하기 위해, 이번 연구에서는 LLM이 스스로 검색 쿼리를 생성하며 Reasoning을 배우는 RL 기반 프레임워크, 바로 Search-R1을 제안했습니다.
 PeterGriffinJin
PeterGriffinJinAbstract & Conclusion
- 기존 방법론(RAG, Tool-Use)은 LLM이 검색 엔진과 상호작용하는 법을 배우지 못함.
- Search-R1은 강화 학습 기반으로 LLM이 다단계로 검색 쿼리를 생성하면서 Reasoning을 수행하도록 훈련.
- 7개의 QA 데이터셋 평가에서 큰 성능 향상:Qwen2.5-7B: 26%Qwen2.5-3B: 21%LLaMA3.2-3B: 10%
Introduction
LLM이 외부 지식을 활용하기 위해서는 RAG와 Tool-Use 크게 두 가지 방법이 있습니다. 하지만 각 방법은 아래와 같은 한계가 있습니다.
RAG (Retrieval-Augmented Generation) - 입력 쿼리를 바탕으로 관련 Passage를 검색하여 Context에 함께 LLM의 Input으로 제공
- 검색된 정보가 관련성이 없을 수도 있음
- Multi-hop retrieval 지원하지 않음
- LLM이 Search Engine과 상호작용 하는 방법을 배우지 못함
Search Engine Tool-Use - Search Engine을 Tool로 활용하도록 학습
- 일반화의 어려움
- 확장성 문제: 훈련 기반 방식은 높은 품질의 대규모 annotated trajectories가 필요함
따라서 저자들은 이러한 문제를 해결하기 위해 강화학습 기반 방법론인 Search-R1을 제안합니다.
- 학습 시 Search Engine과의 상호작용을 학습의 일부로 포함
- Multi-Turn Interleaved Reasoning and Search
- Reward Design
Methodology
그럼 연구팀은 RL을 바탕으로 어떻게 Search Engine과의 상호작용을 학습 시킬 수 있었을까요?
Search-R1의 Objective는 다음과 같습니다.
$$\max_{\pi} E_{x \sim D, y \sim \pi_{\theta}(\cdot | x; R)} \left[ r \phi(x, y)\right] - \beta D_{KL} \left[ \pi_{\theta}(y | x; R) | \pi_{ref}(y | x; R) \right]$$
일반적인 RL Objective와 크게 다르지 않습니다.
$$\pi_\theta(\cdot | x; R)$$
R은 Search Engine을 의미합니다. Policy LLM은 R (Search Engine)과 함께 Reward를 최대화할 수 있도록 학습됩니다. 이를 통해 LLM이 Search Engine과 효과적으로 Interact 하는 방법을 배울 수 있는 것이죠.
굉장히 나이브하면서도 간단한 접근 방식입니다. 🤔
PPO + Search Engine
앞서 정의한 RL objective는 PPO 혹은 GRPO로 학습 (Policy Optimization) 할 수 있다고 합니다. 식은 다음과 같습니다.
\[J_{PPO}(\theta) = E_{x \sim D, y \sim \pi_{old}( \cdot | x; R)} \left[ \frac{1}{\sum_{t=1}^{|y|} I(y_t)} \sum_{t=1}^{|y|} I(y_t) \cdot \min \left( \frac{\pi_{\theta}(y_t | x, y_{<t}; R)}{\pi_{old}(y_t | x, y_{<t}; R)} A_t,\ \text{clip} \left( \frac{\pi_{\theta}(y_t | x, y_{<t}; R)}{\pi_{old}(y_t | x, y_{<t}; R)} , 1 - \epsilon,\ 1 + \epsilon \right) A_t \right) \right]\]
Policy Model에서 Search Engine R을 함께 사용한다는 것을 제외하면 일반적인 PPO의 식과 크게 다르지 않습니다.
한 가지 주목할 점은 검색된 토큰에 대해서는 Loss Masking을 진행했다는 점입니다.
$I(y_t)$ 에서 LLM에 의해 생성된 토큰인 경우, loss를 계산하고 학습에 반영하는 한편, Search Engine에서 검색된 토큰인 경우 loss 계산에서 제외합니다.
이를 통해 LLM이 직접 생성한 것이 아닌 토큰은 학습 과정에서 제외하여 불필요한 학습을 방지하고 학습 안정성을 높일 수 있었다고 합니다.
GRPO + Search Engine
최근 Deepseek로 핫한 GRPO도 활용이 가능합니다.
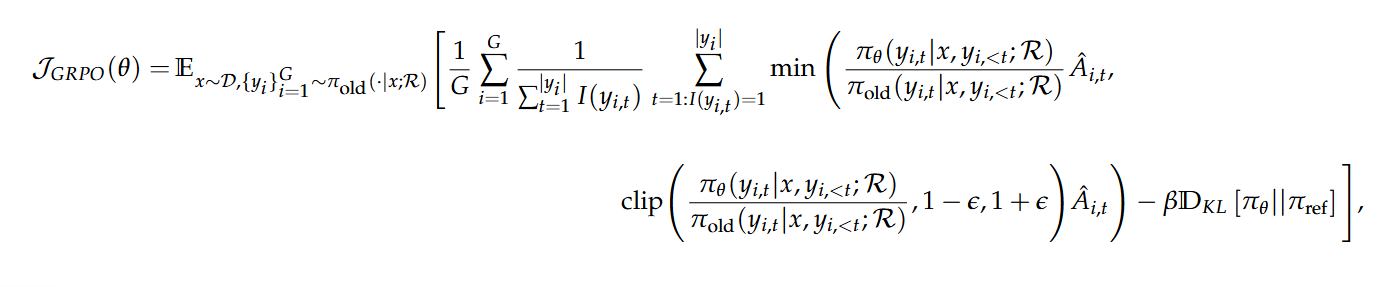
PPO와 마찬가지로 기존 GRPO 식과 크게 다르지 않으며, 검색된 토큰에 대해서는 Loss Masking을 진행하였습니다.
Text Generation with Interleaved Multi-turn Search Engine Call
그렇다면 LLM은 어떻게 생성 (추론)을 진행하는 동안 Search Engine과 상호작용을 할 수 있었을까요?
모델은 3가지 Special Token을 활용합니다.
<search></search>: 해당 토큰 내부의 텍스트는 검색 쿼리로 파싱하여 Search Engine을 호출
<information></information>: 앞서 Search Engine에 의한 검색 결과
<answer></answer>: 최종 응답
그리고 학습을 위해 사용한 Trainiing Template은 아래와 같다고 합니다.
앞서 살펴본 think, search, answer 토큰이 활용되고 있습니다.
Answer the given question. You must conduct reasoning inside <think> and </think>
first every time you get new information. After reasoning, if you find you lack some
knowledge, you can call a search engine by <search> query </search>, and it will
return the top searched results between <information> and </information>. You
can search as many times as you want. If you find no further external knowledge
needed, you can directly provide the answer inside <answer> and </answer> without
detailed illustrations. For example, <answer> Beijing </answer>. Question: question.Reward Modeling
본 프레임워크에서 Reward Model은 어떻게 설계하였을까요?
$$r_\phi(x, y) = EM(a_{pred}, a_{gold})$$
연구팀은 모델이 예측한 답변과 정답 사이의 EM (Exact Match) Score를 사용하였습니다. 대표적인 다른 Reward Model 방법 중 하나인 Neural Reward Model은 Reward Hacking (모델이 오히려 편법으로 Reward만 높이려 해서 점수가 향상되지 않는 현상)과 계산 비용 및 복잡성 문제가 있었다고 합니다.
또한 Deepseek-R1에서 활용한 format reward는 모델이 이미 구조적 규칙을 잘 따르기 때문에 별도로 적용하지 않았다고 합니다.
Main Results
연구팀은 평가를 위해 7가지 QA 데이터셋을 활용하여 평가 벤치마크를 구성하였습니다. (General QA: NQ, TriviaQA / Multi-Hop Question Answering: HotpotQA, 2WikiMultiHopQA, Musique, Banboogle)
비교 평가를 위해 3가지 비교군을 채택하였습니다.
- Inference without Retrieval
- External Knoledge 없이 Direct Inference 혹은 CoT 추론
- Inference with Retrieval
- RAG, IRCoT, Search-o1
- Fine-Tuning-Based Methods
- SFT
- R1 (without a Search Engine)
그리고 Qwen-2.5-3B(Base/Instruct), Qwen-2.5-7B(Base/Instruct), Llama-3.2-3B(Base/Instruct)를 활용하여 학습을 진행하였고,
Retriever로는 E5를 활용하여 Wikipedia dump를 제공했다고 합니다.
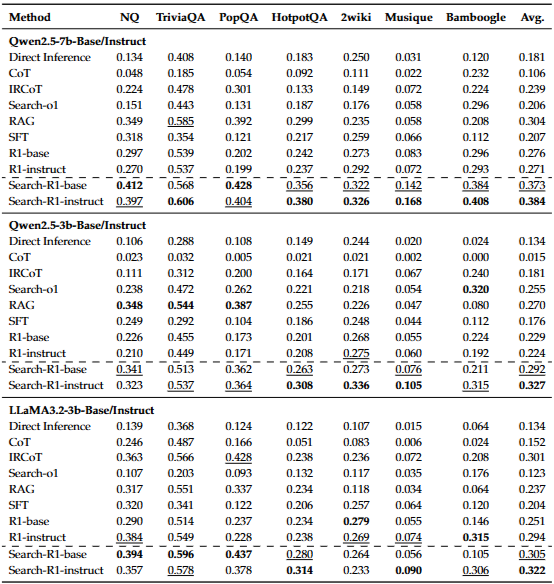
결과는 위와 같습니다.
대부분의 데이터셋에서 높은 성능을 보이고 있습니다.
Analysis
개인적으로 흥미롭게 읽었던 부분입니다!
연구팀은 Search-R1 Method에서 여러가지 비교 실험을 진행하였는데요,
GRPO vs PPO
- GRPO는 PPO보다 빠르게 수렴, PPO는 critic model을 사용하기 위한 초기 학습에서 준비 단계가 필요함
- PPO는 GRPO보다 훈련 안정성이 더 높음
- PPO와 GRPO의 최종 훈련 보상은 비슷함
- 모델 별로도 다른 양상을 보일 때도 있음

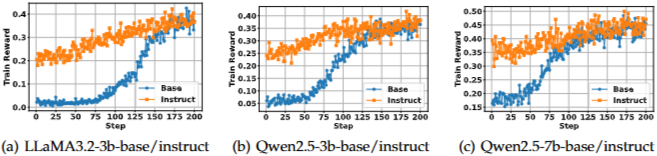
Base vs Instruct
- Instruct 모델이 초기 성능도 높고 수렴 속도도 더 빠름
- 하지만 훈련이 진행됨에 따라 Base 모델은 Instruct 모델과 비슷한 수준의 성능에 도달할 수 있음
- RL이 일반적인 SFT와 Pre-training 간의 격차를 해소할 수 있다고 주장
Response Length Study
- LLaMA3.2-3b-base 모델 기반, NQ 데이터셋으로 훈련
- 초기 단계 (~100 스텝)
- 응답 길이가 급격히 감소
- 훈련 reward은 약간 증가
- 모델이 불필요한 단어를 제거하고 작업 요구 사항에 적응
- 중간 단계 (100-130 스텝)
- 응답 길이와 훈련 보상이 모두 크게 증가
- LLM이 Search Engine을 호출하는 것을 학습하여 검색 결과로 인한 응답이 길어짐
- 모델이 검색 결과를 효과적으로 활용하여 훈련 reward가 크게 향상
- 후기 단계 (130 스텝 이후)
- 응답 길이가 안정화
- 훈련 Reward는 계속 약간 증가
- 모델이 Search Engine을 효과적으로 사용하는 방법을 학습하고 Search Query를 개선하는데 집중
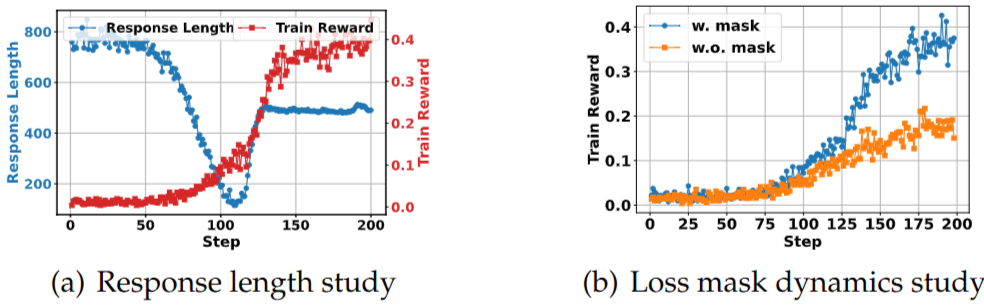
Study of Retrieved Tokens Loss Masking
- Loss Masking을 적용하면 학습이 더욱 안정적으로 진행되고, 전반적인 성능이 향상됨.

마치며
Search-R1은 단순한 RAG나 툴 사용을 넘어서, LLM이 스스로 Reasoning 과정 속에서 검색을 전략적으로 활용하도록 RL 전략으로 학습시킨 점이 인상 깊었는데요,
최근 LLM의 Reasoning 및 Agent 연구들이 활발해지고 있는데, Search-R1은 이 흐름 속에서 Search Engine을 LLM에 어떻게 녹여낼 수 있을지 흥미로운 관점을 제시한다고 생각합니다.
감사합니다 😊
![[번역] The Second Half](https://images.unsplash.com/photo-1760592150404-adacb88548e2?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDJ8fHx8fHx8fDE3NjA2NTUzOTJ8&ixlib=rb-4.1.0&q=80&w=600)
![[논문 리뷰] ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS](https://images.unsplash.com/photo-1499428665502-503f6c608263?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDcyfHx8fHx8fHwxNzUyNDgwODc3fA&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 5편 (완)](https://images.unsplash.com/photo-1749225595496-06cd2c49fa2b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDZ8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 4편](https://images.unsplash.com/photo-1749221836725-494abefcd2a0?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDd8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)