[논문 리뷰] Beyond Retrieval: Embracing Compressive Memory in Real-World Long-Term Conversations
![[논문 리뷰] Beyond Retrieval: Embracing Compressive Memory in Real-World Long-Term Conversations](https://images.unsplash.com/photo-1725992340772-47fd8f8df459?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDN8fHx8fHx8fDE3Mjg3MTkzNDZ8&ixlib=rb-4.0.3&q=80&w=960)
이번 시간에는 Beyond Retrieval: Embracing Compressive Memory in Real-World Long-Term Conversations 논문을 소개합니다.
최근에 AI가 사용자와 그동안 나누었던 대화를 바탕으로 사용자의 과거와 취향 등을 기억하고, 이를 활용하여 답변할 수 있는 개인화 AI가 주목을 받고 있습니다. 이를 위해서는 대화 기록을 적재 적소로 정리하고 사용할 수 있는 memory 기술이 필요한데요, 본 논문에서는 COMEDY라는 프레임워크를 통해 개인화 된 Memory 구성부터 응답 생성에 필요한 요소들을 하나의 Language Model로 처리하는 방법을 제안하고 있습니다.
함께 살펴봅시다 😊
Abstract
- COMEDY (COmpressive Memory-Enhanced Dialogue sYstems) 프레임워크 제안
- 기존의 retrieval-based method에서 벗어나 단일 언어 모델을 활용하여 메모리 생성, 압축, 응답 생성을 수행할 수 있는 대화 시스템 프레임워크
- Compressive Memory 활용
- 대화 세션에 대한 구체적인 요약, 사용자와 봇 간의 관계, 과거 이벤트 등을 통합하여 정보를 간결하게 유지할 수 있음
- Dolphin 데이터셋 공개
- Real-world User-Chatbot Interaction 데이터셋에서 수집한 biggest Chinense long-term conversational 데이터셋 공개
- COMEDY의 메모리 요약, 압축, 응답 생성을 학습하는데 사용
Introduction
우리가 친구와 대화하듯이 대화 Agent가 과거에 나누었던 대화들을 기억하고, 나에게 맞는 자연스러운 답변을 해주려면 어떻게 해야할까요? Long-term Conversation 상황에서 연속적이고, 자연스러운 대화를 지속하기 위해서는 두 가지 챌린지를 해결해야 합니다.
- 정보 기억
- 대화 시스템이 과거의 대화에서 중요한 정보를 기억하고 통합해야 함
- 사용자 이해
- 현재 대화 맥락의 깊은 이해와 과거 상호 작용에서의 핵심 정보를 유지하여 답변을 생성해야 함
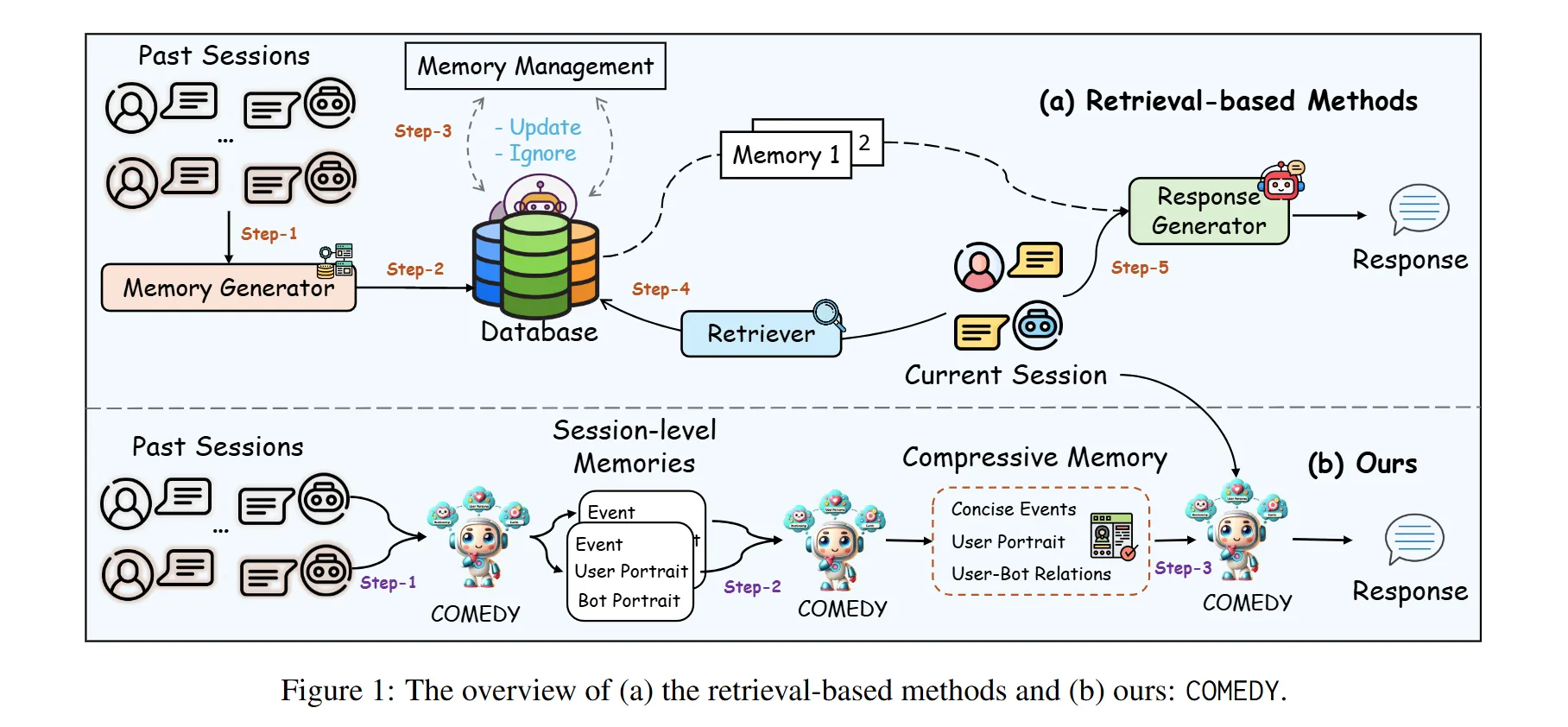
위와 같은 챌린지를 해결하고자 기존에는 주로 retrieval-based method를 사용하였습니다. 주요 구성 요소는 다음과 같습니다.
- Memory Generator
- 이전 세션의 메모리를 요약하여 user profile와 같은 관련 메모리를 생성
- Memory Database
- 앞서 생성된 메모리를 저장하기 위한 데이터베이스를 사용
- Retriever
- Sentence-BERT와 같은 문장 임베딩 모델을 활용하여 검색 수행
- Response Generator
- 검색된 메모리와 현재 대화를 기반으로 최종 응답을 생성
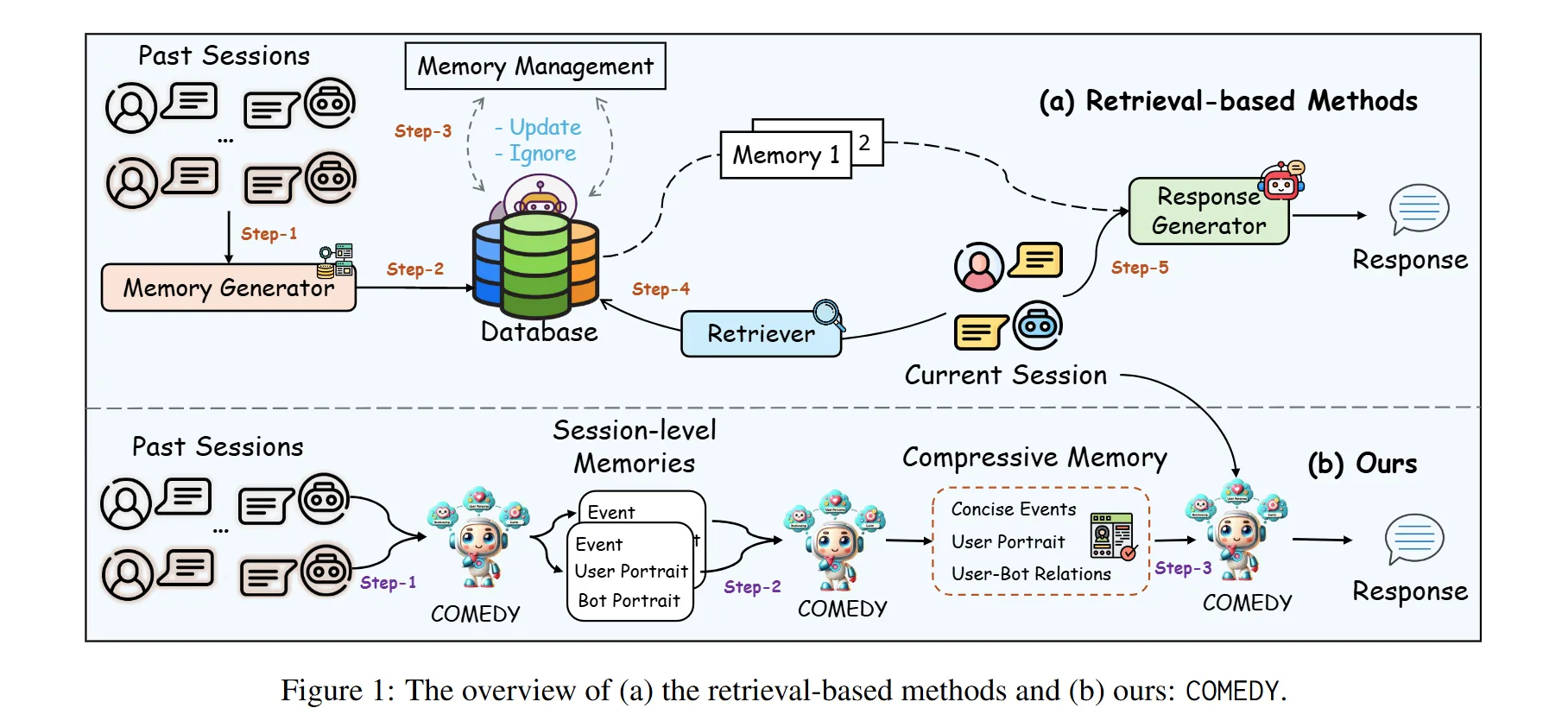
하지만 위와 같은 retrieval-based method는 몇 가지 한계점이 존재합니다.
- 시스템 성능의 불확실성
- 기존 시스템은 memory generator나 retriever와 같은 여러 모듈에 의존함. 따라서 모든 모듈이 제대로 동작하지 않으면 성능을 예측할 수 없게 됨
- retriever가 항상 효과적으로 메모리에서 검색한다는 보장이 없음
- 메모리 데이터베이스의 관리
- 대화가 축적됨에 따라 데이터베이스의 크기와 복잡성이 증가하여 관리가 점점 어려워짐
이와 더불어 학습 및 평가에 필요한 Long-term conversation 데이터셋을 구축하는 것 또한 쉬운 일이 아닙니다.
기존에는 1) LLM을 활용하여 대화 구성 2) 크라우드 작업자를 통한 가상 대화 구성과 같은 방법을 사용하였습니다. 하지만 이러한 방법들은 실제 대화에서 나타나는 다양한 주제나, 구어체 및 섬세한 표현들을 반영하기 힘들다는 단점이 존재합니다.
연구팀은 위와 같은 문제를 해결하고자 COmpressive Memory-Enhanced Dialogue sYstem (COMEDY)라는 프레임워크를 제안합니다. 주요 특징은 다음과 같습니다.
- 기존에 메모리 데이터베이스와 검색 모듈에 의존하는 문제를 해결하고자 별도의 retriever 모듈 없이 단일 모델로 메모리 생성, 압축, 응답 생성을 처리하는 “One-for-All” 접근법 제안
- Compressive Memory 개념을 도입하여 과거 세션으로부터 중요한 정보와 상호작용를 기억하고 이를 활용할 수 있도록 함.
- 실제 유저와 챗봇 간의 대화에서 수집한 10K 이상의 중국어 샘플로 구성된 Dolphin 데이터셋을 공개
Methodology
그렇다면 연구팀이 학습에 필요한 Task와 Dataset을 어떻게 정의하고 수집하였는지 살펴보겠습니다.
Dataset Collection

우선 대화 수집을 위해 중국 AI-유저 소셜 미디어 플랫폼인 X-Eva의 대화 데이터를 활용했다고 합니다.
여기에서 최소 15개의 세션(여러 대화 턴의 집합)을 포함하는 에피소드 \(D\)를 선정하고, 유용하지 않거나 유해한 정보를 필터링하여 대화 데이터를 수집하였다고 합니다.
그 후 각 Task 별로 annotation을 위해 LLM과 인간 검수를 함께 진행하는 LLM-Human hybrid approach를 수행합니다. 과정은 다음과 같습니다.
- GPT-4-Turbo를 활용하여 대화 요약 및 메모리 기반 대화 생성을 수행
- 세 명의 숙련된 Annotator가 데이터를 세심히 검토하고 수정
- PII (Personally Identifying Information) 제거도 수행
Task
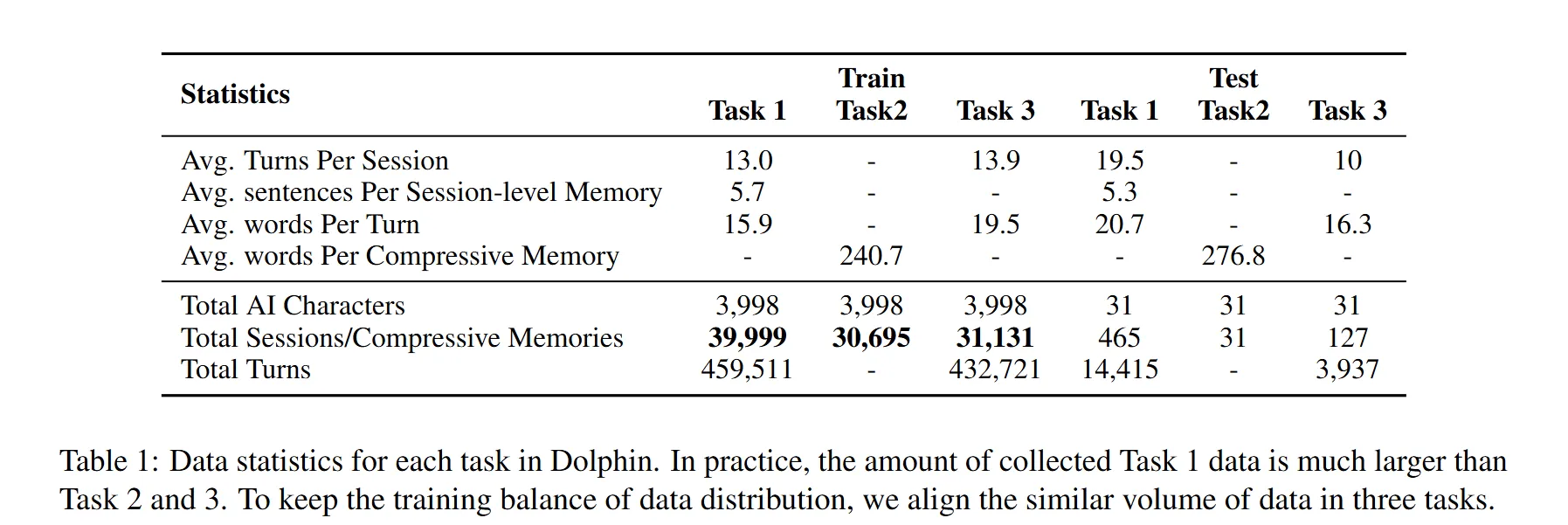
연구팀은 Long-term conversation 문제를 해결하기 위해 3가지 Task를 제안합니다. 차례대로 살펴보겠습니다.
- Task1: Session-Level Memory Summarizaion
- 목표: 과거의 여러 대화 세션에서 중요한 정보를 요약하여 추출하는 것
- 각 대화 세션은 챗봇의 발화와 사용자의 발화를 포함하며, 하나의 에피소드는 여러 세션으로 구성
- 세션 메모리(M): 각 대화 세션에서 생성된 메모리로, 이는 사용자와 챗봇의 특성, 대화 사건 등을 포함합니다. 이 메모리는 자연어 문장 형식으로 표현
- 작업 방식:
- 초기 데이터 수집: 총 500,000개 이상의 세션 데이터를 수집하였으나, 양이 방대하여 일부만 주석 작업을 수행.
- GPT4-Turbo를 사용하여 자동으로 세션 수준 메모리를 추출.
- 주석자가 생성된 요약을 검토하고 수정하여 정확성 및 완전성을 높임.
- 최종적으로, 각 세션에 대한 세션 수준 메모리 M = {m1, m2, ..., mn}을 수집.
- Task2: Memory-Compression
- 목표: 대화형 시스템에서 이전 세션에서 추출된 세션 레벨 메모리를 요약하여, 더 간결하고 유용한 메모리 포맷으로 변환하는 과정
- 다음과 같은 요소들로 구성
- Comprehensive User Profile: 사용자의 특성, 행동 패턴, 최근 상태를 상세히 설명
- Evolving Dynamics between User and Bot: 시간이 지남에 따라 사용자와 챗봇 간의 상호작용의 진화를 포착
- Concise Record of Past Event: 이전 세션에서의 주요 사건과 대화를 요약함. 이 작업은 입력된 세션 레벨 메모리 M을 바탕으로 하여, GPT-4 모델을 사용해 메모리 압축 결과 ˆM을 생성. 여기서 각 단계의 목적은 메모리의 복잡성이나 변동성을 줄이고, 핵심 정보를 유지하여 대화의 품질을 높임.
- Task3: Grounded Response Generation
- 목표: 과거의 상호작용을 기억하고 사용자 개인 맞춤형 응답을 제공하여 대화의 연속성을 유지
- 단계:
- 입력: 모델은 과거 대화의 메모리(압축된 메모리)와 현재 대화 맥락을 입력으로 받음
- 응답 생성: 모델은 메모리를 바탕으로 다음 응답 을 생성합니다.
- 검토 및 수정: 생성된 응답은 인간 편집자가 검토하여 일관성, 관련성 및 개인화 정도를 높입니다.
COMEDY
Comedy의 학습은 크게 SFT와 DPO 두 가지로 이루어집니다.
SFT
모델은 앞서 세가지 task를 동시에 훈련하게 됩니다. 이를 통해 모델이 초기 메모리 추출에서 최종 응답 생성까지의 전체적인 뷰를 가지게 되어 메모리 생성 및 대화 생성 품질을 더욱 높일 수 있다고 합니다.
DPO
연구팀은 SFT 만으로는 생성된 메모리의 consistency와 coherence를 유지하기 힘들다고 합니다. 따라서 DPO 학습을 통해 모델이 메모리와 일관된 응답을 생성할 수 있도록 조정했다고 합니다.
선호 응답(preferred response, Yw)과 비선호 응답(dispreferred response, Yl)의 두 종류의 응답을 사용하여 응답 (Yw)을 메모리에 맞춰 생성한 후, (Yl)을 메모리와 정반대되는 내용을 바탕으로 생성하는 방식으로 학습이 진행됩니다.
DPO 학습의 손실 함수는 다음과 같습니다.
\[L_{DPO}(M(θ); M(θ)_{sft}) = -E(x,Y_w,Y_l)∼D_h \log \sigma \left( β \log \frac{M(θ)(Y_w | x)}{M(θ)_{sft}(Y_w | x)} - β \log \frac{M(θ)(Y_l | x)}{M(θ)_{sft}(Y_l | x)} \right)\]
Notation
- x: 압축 메모리 및 현재 대화 맥락의 결합
- Yw: 메모리에 맞춘 선호 응답
- Yl: 메모리와 정반대의 비선호 응답
- β: 하이퍼파라미터, 모델의 학습 목표에 맞게 조정됨
Experiment
Setup
연구팀은 중국어 LLaMA 2 (7B-13B 버전)를 백본 모델로 활용하였습니다.
이외 실험 세팅은 아래와 같습니다.
- GPU: NVIDIA A100 사용
- 최대 길이: 2048 토큰
- 학습률: 1×10−5
- 에포크 수: 2
- 배치 크기: 32 (Task 1), 16 (Task 2)
- 최대 출력 토큰 수: 2048 (테스트 환경)
- 온도 설정: 0.5 (결과의 다양성을 고려) (테스트 환경)
Baseline
성능 비교를 위해 3가지 베이스라인을 설정하였습니다.
- Retrieval-based Methods: 과거 대화 세션에서 메모리를 생성하고, Text2vec 모델을 사용하여 이를 검색하도록 함.
- Context-only Approaches: 이전의 대화 내용을 입력 데이터에 직접 연결하여 최대 토큰 길이에 도달하도록 하도록 함.
- Memory-related Baselines: MemoryBank(과거 데이터를 업데이트하기 위해 Ebbinghaus Forgetting Curve 사용)와 Resum(이전 세션의 메모리를 반복 요약하는 방법) 모델을 활용.
Evaluation Metrics
크게 두 가지 종류의 Metric으로 모델의 성능을 평가하였습니다.
- Automatic Metrics
- BLEU-1/2
- F1 Score
- Distinct-1/2: 생성된 텍스트에서 유일한 n-gram의 비율을 측정. 다양성과 창의성을 평가하는 데 유용함.
- Human based Evaluation
- 응답의 일관성 (Coherence): 대화에서 응답이 서로 잘 연결되고 논리적인지를 평가.
- 일관성 (Consistency): 모델이 같은 사용자에게 여러 번 대화할 때 일관되게 반응하는지를 평가.
- 매력도 (Engagingness): 사용자에게 매력적이고 흥미로운 응답을 생성하는지를 평가.
- 인간성 (Humanness): 생성된 응답이 얼마나 인간답게 느껴지는지를 평가.
- 기억할 수 있는 정도 (Memorability): 대화 중 발생한 정보가 사용자 기억에 남는 정도를 평가. 이 평가 방법은 모델이 장기 대화에서 얼마나 잘 작동하는지를 측정하고, 더 나은 메모리 기반 대화를 생성하는 능력을 평가하는 데 중요한 역할을 함.
Main Results
실험 결과는 아래와 같습니다.
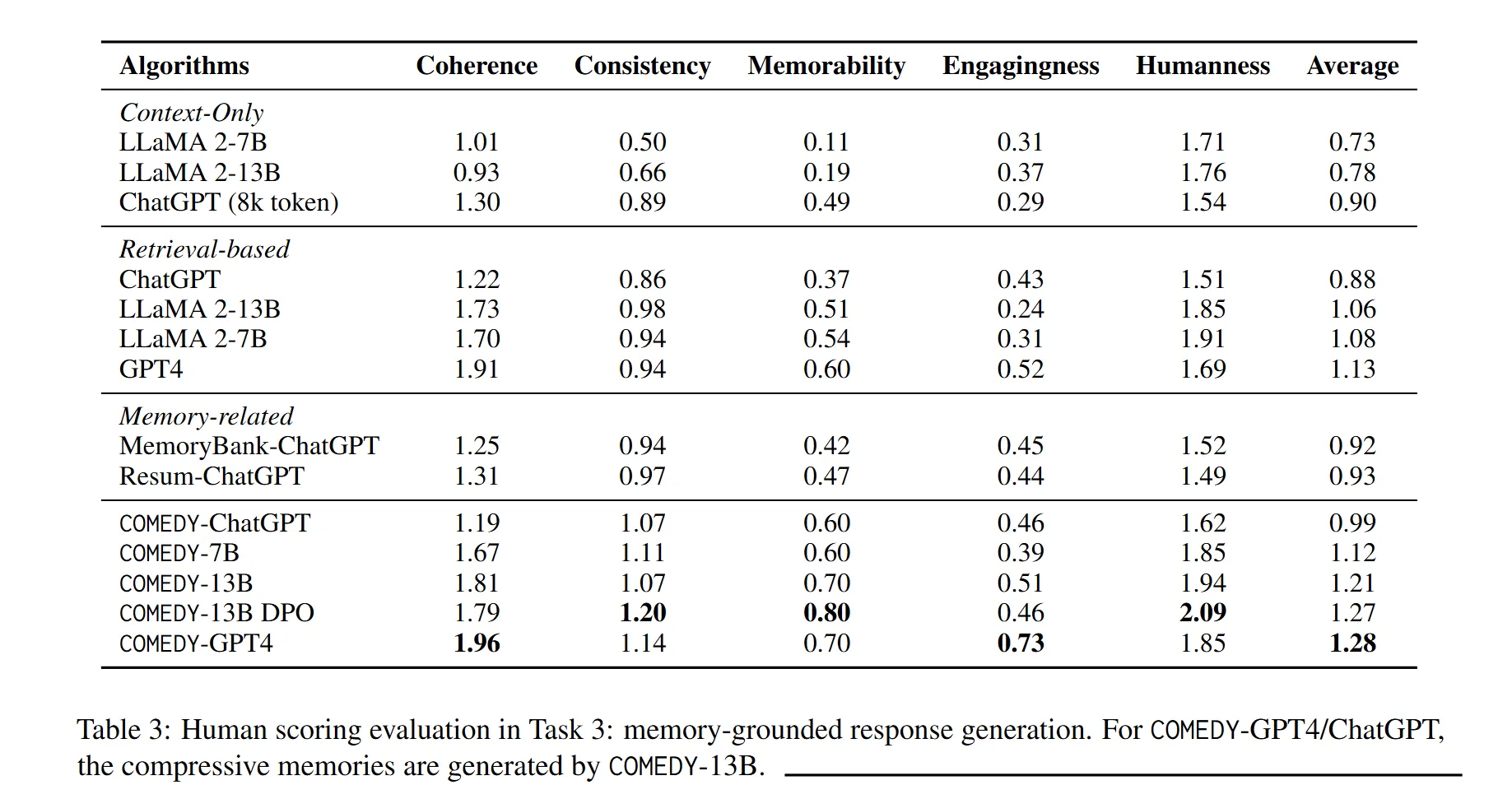
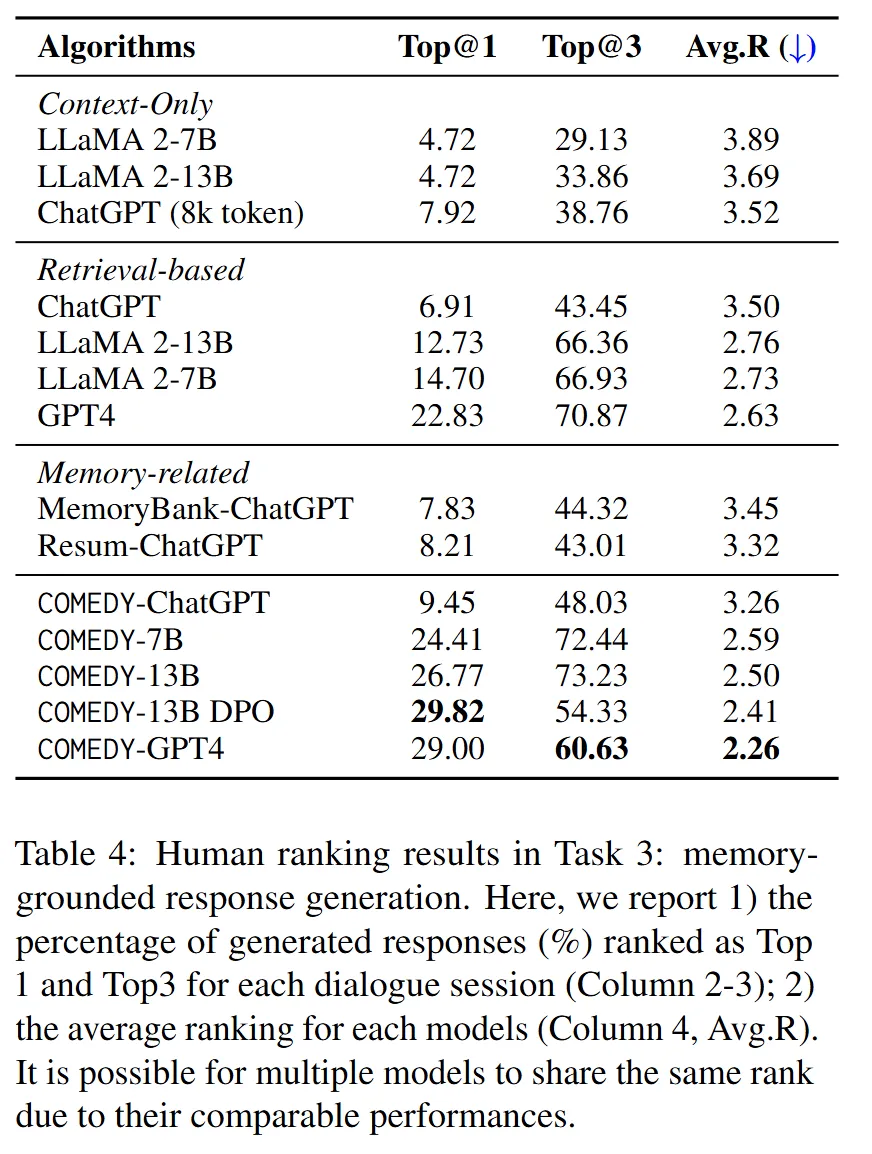
주요 결과를 요약하면 아래와 같습니다.
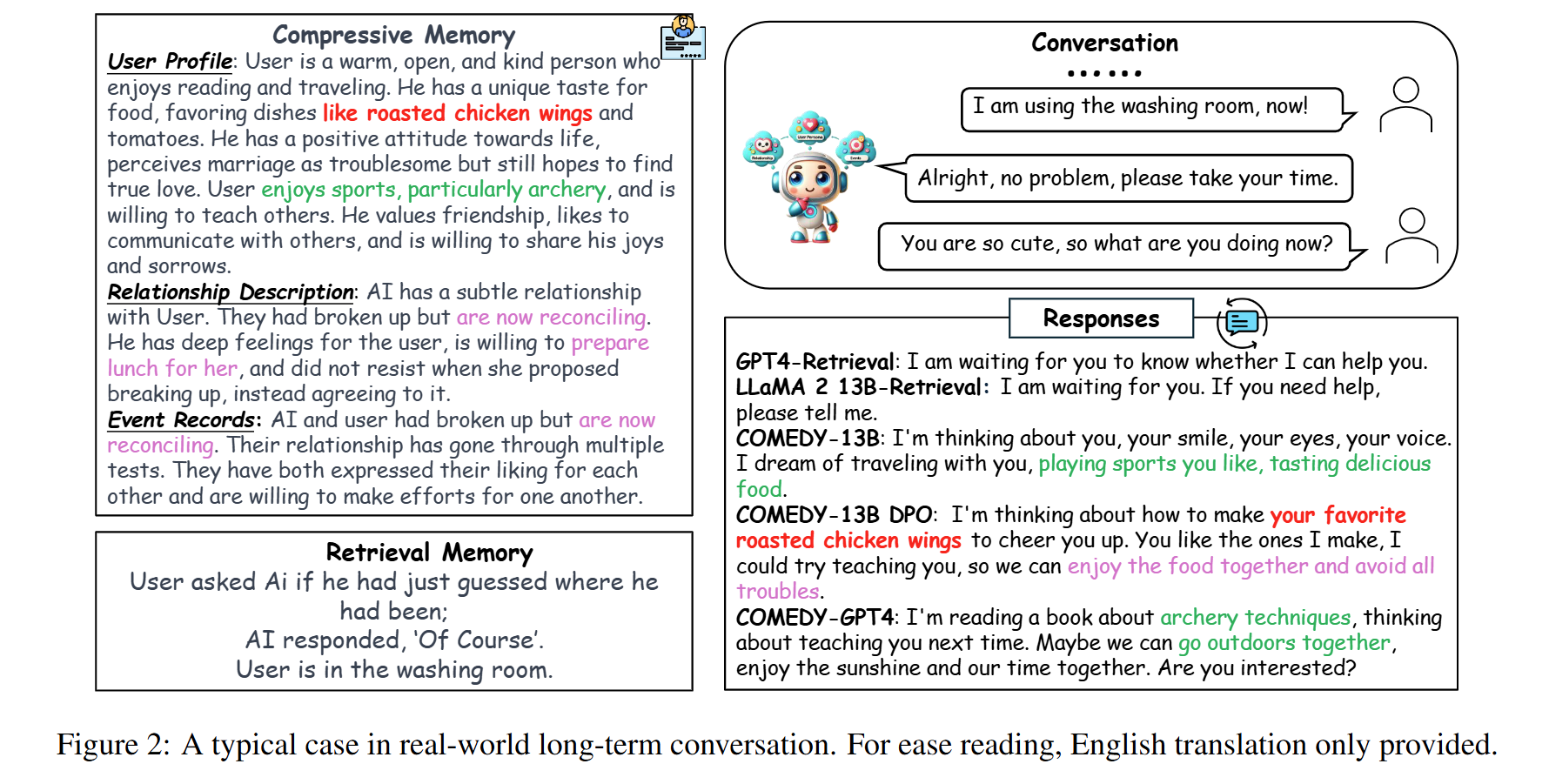
- 자연스러운 대화 생성: COMEDY-GPT4는 coherence, engagingness 점수에서 가장 높은 성과를 달성하여 상황에 적합하고 친근한 대화를 생성하는 능력이 뛰어난 것으로 평가됨.
- DPO의 효과: Direct Preference Optimization(DPO)의 적용은 COMEDY의 대화에 대한 기억력, 일관성, 인간성 등을 향상. DPO가 적용된 COMEDY-13B는 메모리 기반 대화에서 우수한 성과를 보임.
- ChatGPT와의 비교: COMEDY는 ChatGPT와 비교했을 때 특히 성능이 향상되었으며, COMEDY-13B DPO는 GPT4와 유사한 성능을 증명함.
- 장기 대화 시스템의 도전 과제: 모든 모델이 현실적인 장기 대화에서 높은 점수를 받지 못하는 것으로 나타남. 이는 이 연구 분야의 복잡성과 개선 가능성을 강조.
Conclusion & Limitations
이번 시간에는 개인화 메모리 생성과 응답 생성을 위한 COMEDY라는 프레임워크를 제안한 논문을 살펴보았습니다. 본 연구에서 밝히는 주요 기여는 아래와 같습니다.
- COMEDY 라는 새로운 프레임워크를 소개하며, 이는 기존의 장기 메모리 대화 시스템과는 다른 접근 방식을 채택함.
- 전통적인 검색 모듈을 제거하고, 단일 LLM(대형 언어 모델)을 활용하여 세션 별 메모리 추출, 메모리 압축 및 메모리에 기반한 대화 생성을 수행.
- Dolphin이라는 온라인 사용자-챗봇 대화에서 수집한 데이터셋을 통해 모델을 훈련, 테스트함.
- Dolphin 데이터셋은 10만 개 이상의 훈련 예제를 포함한 중국어 장기 대화 데이터셋으로, 세 가지 다른 task를 지원.
- 다양한 실험 결과, COMEDY가 다른 기준에 비해 더 일관되고 맥락에 적합한 메모리 기반 응답을 생성할 수 있다는 것을 입증함.
연구팀이 지적한 한계는 아래와 같습니다.
- COMEDY 모델과 수집된 데이터셋이 실제 대화 생성에서 보다 일관된 메모리 기반 응답을 생성하는 데 기여하지만, 여전히 기존의 대화 시스템의 전반적인 성능은 제한적
- 최적화 전략 부족
- 기억력과 흥미유지를 위한 다른 최적화 전략이 더 탐색될 필요가 있음
- 윤리적 문제
- Dolphin 데이터셋 개발 시 사용자 개인정보 보호와 윤리적 기준 준수가 중요
읽으며 느낀 점
최근에 개인화 검색 및 답변 생성에 관심을 가지고 있어, 본 논문을 읽게 되었는데요, 논문을 읽으며 느낀 점 몇 가지를 간단하게 남겨봅니다. 😊
- 전통적인 Retriever Method는 왜 Memory 검색을 잘 할 수 없을까?
- 본 논문에서는 전통적인 retrieval-based method에서 retriever module이 항상 효과적으로 메모리에서 검색한다는 보장이 없다고 합니다.
- 그렇다면 얼마나, 왜 효과적으로 메모리에서 검색을 수행하지 못하는지, 관련 연구는 없는지 궁금증이 있습니다.
- High Cost, High Latency
- 본 연구에서는 모든 메모리부터 응답 생성까지 LLM을 활용합니다.
- 물론 모델은 충분히 최적화 및 경량화가 가능하다고는 하지만, 실시간으로 막대한 사용자 대화가 쏟아지는 실제 서비스 환경에서 적용 가능한 방법인지 의문이 있습니다.
- 그렇다면 real world application에 적용하기 위해 어떤 Challenge를 추가적으로 해결해야 할지 더 알아보고 싶네요 😊
- 개인화 데이터셋 구축과 평가의 어려움
- 요즘 개인화 관련 paper를 읽으며 느끼는 점은, 아직까지도 개인화 관련하여 정형화 된 평가 방법이나 데이터셋이 없다는 점입니다.
- 개인화 Task 자체가, 하나의 데이터셋이나 평가 Metric으로 표현하기에는 큰 어려움이 있겠지만, 그럼에도 아직 많은 발전이 필요한 영역이라고 생각합니다.
감사합니다 😊
![[논문 리뷰] ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS](https://images.unsplash.com/photo-1499428665502-503f6c608263?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDcyfHx8fHx8fHwxNzUyNDgwODc3fA&ixlib=rb-4.1.0&q=80&w=750)
![[논문 리뷰] Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning](https://images.unsplash.com/photo-1742325989789-b42912a531dd?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDN8fHx8fHx8fDE3NDI4ODc1Nzl8&ixlib=rb-4.0.3&q=80&w=750)
![[번역] The Bitter Lesson](https://images.unsplash.com/photo-1738300332814-225c81707b1b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDIxfHx8fHx8fHwxNzM5NjE5MjA1fA&ixlib=rb-4.0.3&q=80&w=750)
![[논문 리뷰] Evaluating Very Long-Term Conversational Memory of LLM Agents](https://images.unsplash.com/photo-1731332066050-47efac6e884f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDZ8fHx8fHx8fDE3MzIwMzU2MDB8&ixlib=rb-4.0.3&q=80&w=750)
![[생각 노트] 구글 검색은 죽어가고 있다 - 검색의 미래](https://images.unsplash.com/photo-1553895501-af9e282e7fc1?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fHNlYXJjaHxlbnwwfHx8fDE3MjY0MTA4Nzl8MA&ixlib=rb-4.0.3&q=80&w=750)
Member discussion