[논문 리뷰] COIL: Revisit Exact Lexical Match in Information Retrieval with Contextualized Inverted List
![[논문 리뷰] COIL: Revisit Exact Lexical Match in Information Retrieval with Contextualized Inverted List](https://images.unsplash.com/photo-1722641277067-a7fba0ad1a59?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDR8fHx8fHwyfHwxNzIyOTYxMjgzfA&ixlib=rb-4.0.3&q=80&w=1200)
이번 시간에는 COIL: Revisit Exact Lexical Match in Information Retrieval with Contextualized Inverted List 논문에 대해서 살펴봅니다.
COIL은 기존 BM25와 같은 Exact lexical match 방식과 ColBERT와 같은 Dense Retriever의 장점을 합친 모델입니다. 이를 통해 적은 컴퓨팅 비용으로도 당시의 SOTA deep LM Retriever과 유사한 성능을 내는 점이 특징입니다.
논문은 링크에서 확인할 수 있습니다.
더불어 Retriver 성능 개선과 관련하여 이전에 리뷰한 XTR 논문과 함께 읽어보셔도 큰 도움이 됩니다!
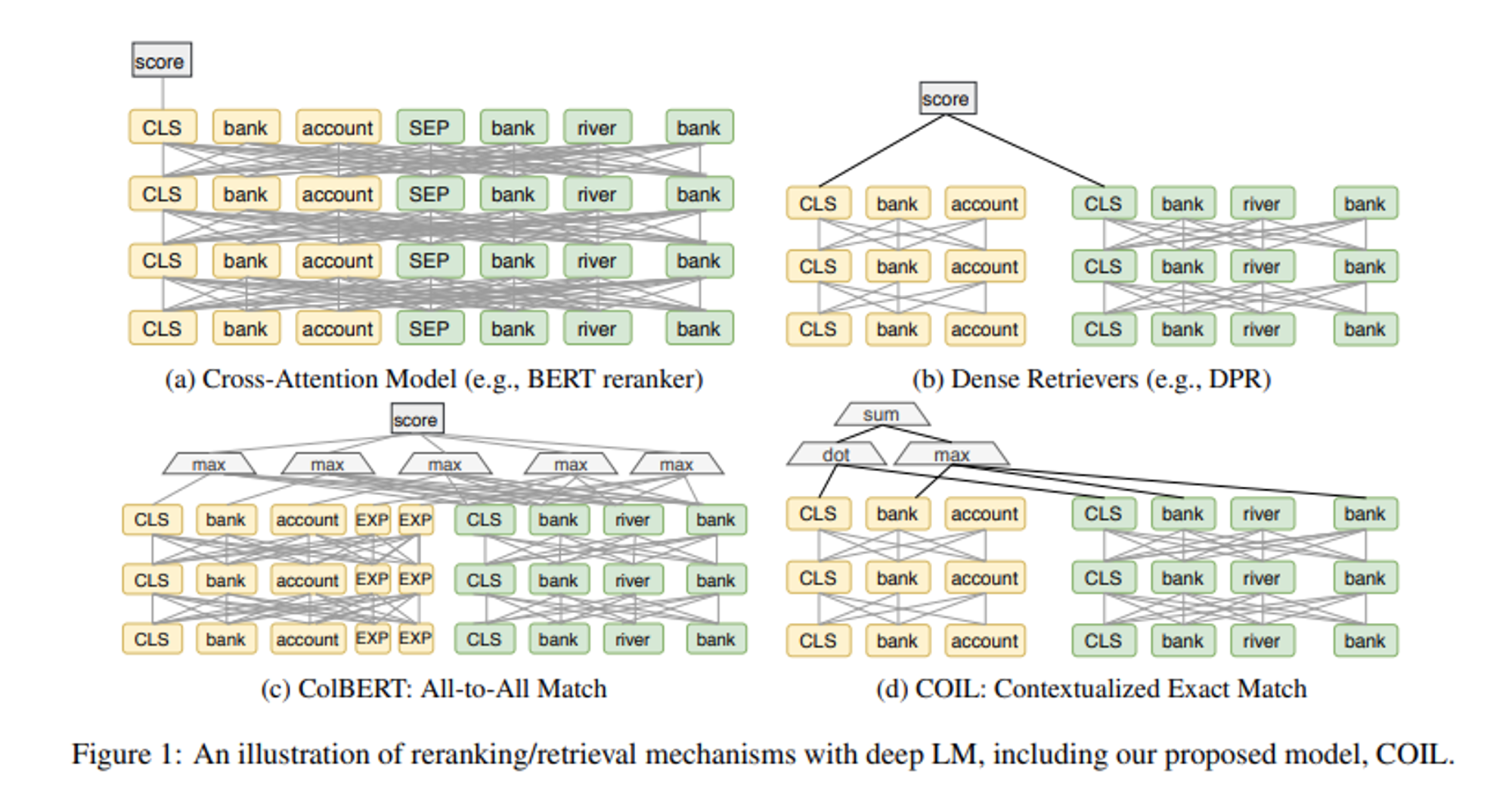
Methodologies
Preliminaries
논문이 발표된 2021년 당시, DPR와 ColBERT와 같은 Dense Retriever 모델을 중심으로 한 연구가 활발하게 이루어지고 있었습니다. Dense Retriever는 BERT와 같은 딥러닝 모델을 활용하여 쿼리와 문서의 임베딩을 생성하고 비교하는 방식으로, 기존의 Sparse Retriever와 비교하여 문장의 문맥적이고 의미적인 표현을 보다 잘 살릴 수 있어 검색 성능을 높일 수 있는 장점이 있습니다.
그렇다면 연구팀은 왜 BM25와 같은 exact lexical match 방식을 COIL에 도입하고자 했을까요?
가장 큰 이유는 바로 효율성입니다.
우선 쿼리 용어와 정확히 일치하는 문서에 대해서만 점수를 매기면 됩니다. 또한 용어들에 대한 점수를 미리 Inverted Index List에 저장함으로써, 필요한 문서와 용어를 효율적으로 빠르게 검색할 수 있습니다.
이를 통해 연구팀은 exact lexical match 시스템의 효율성을 유지하면서도, 신경 정보 검색을 통해 의미적인 정보도 살려 성능을 향상시키고자 했습니다.
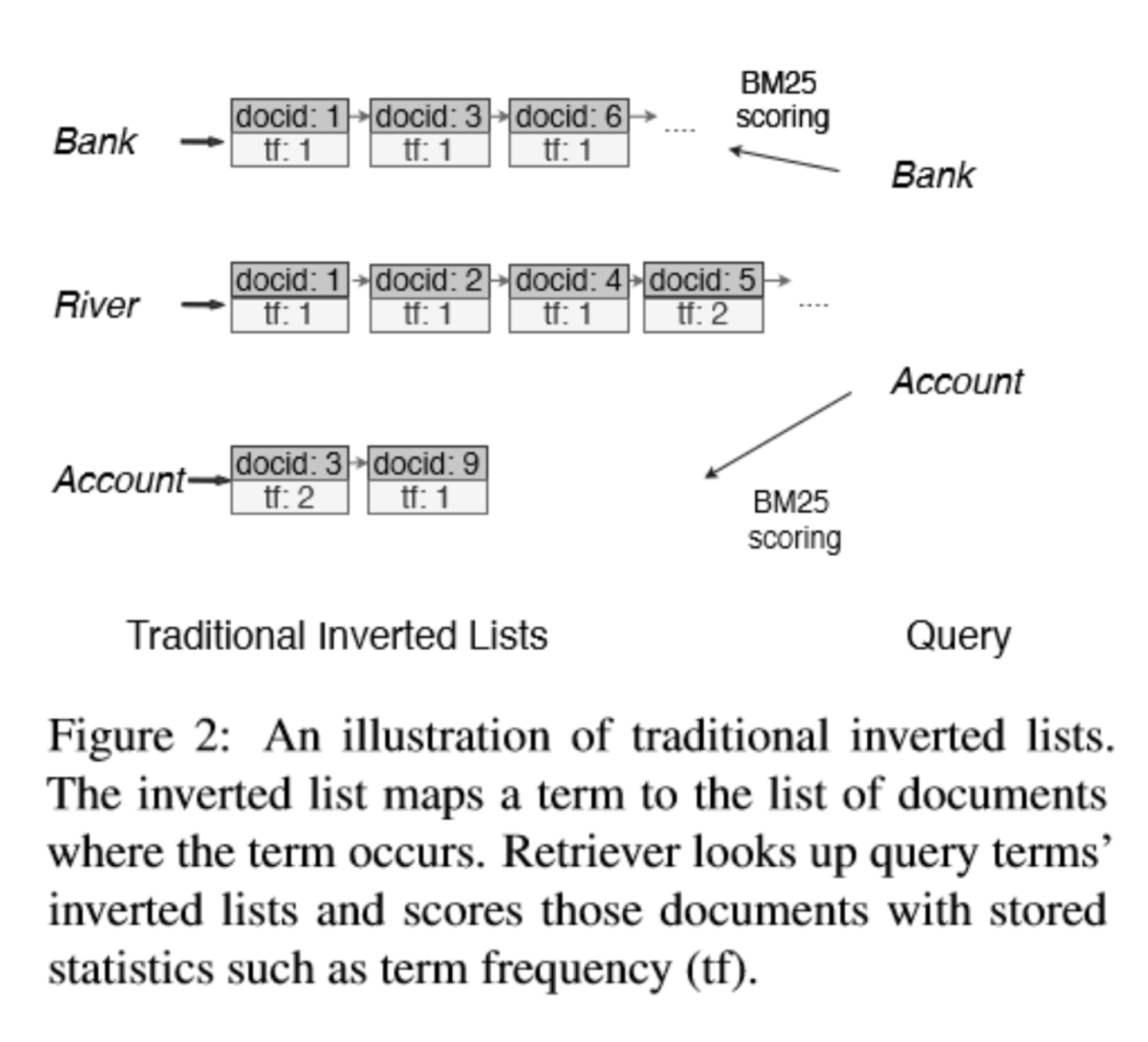
Contextualized Exact Lexical Match
COIL이 어떻게 동작하는지 살펴봅시다.
우선 기존 Dense Retriver 방법론들처럼 query와 document 별로 각 token의 contexualized vector representation을 계산합니다.
\[v^q_i = W_{tok}LM(q,i) + b_{tok} \]
\[v^d_j = W_{tok}LM(d,j) + b_{tok}\]
그리고 query와 document 간의 contextualized exact lexical match scoring function을 구합니다.
scoring function은 아래와 같습니다. query와 document의 token 쌍 중에서 exact match하는 token 들의 vector similarities를 구합니다. 이때 Max 연산을 통해서 같은 token이 여러 개 있을 때 가장 중요한 토큰만을 고려할 수 있도록 한다고 합니다.
\[s_{tok}(q,d) = \sum\limits_{q_i\in q \cap d}^n \max \limits_{d_j=q_i}(v_i^{q\intercal}v_j^{d}) )\]
위 방식을 논문에서는 COIL-tok이라고 부릅니다.
더불어 연구팀은 COIL-tok에서는 vocabulary mismatch 문제가 발생할 수 있다는 점을 지적하며, CLS 토큰을 활용하는 COIL-full 방식도 제안합니다. 기존 COIL-tok에 query와 document의 CLS vector를 고려할 수 있는 term이 추가되었습니다. 이를 통해 lexical-different term 사이에서의 score도 효과적으로 고려할 수 있다고 합니다.
\[s_{full}(q,d) = s_{tok}(q,d) + v_{cls}^{q}\intercal v_{cls}^d\]
위 scoring function을 활용하여 아래 수식을 최소화하도록 모델은 학습됩니다. 이때 batch negative로 BM25를 활용하여 hard negative를 생성했다고 합니다.
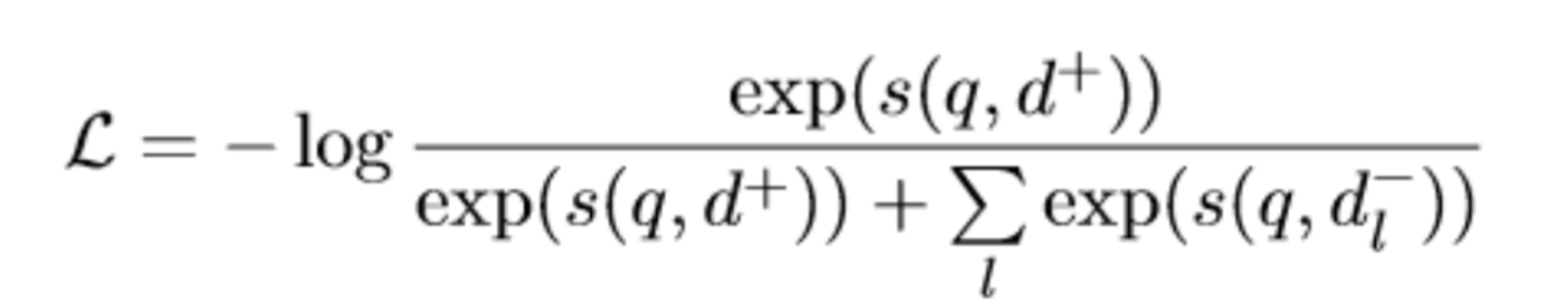
Index and Retrieval with COIL
COIL에서는 미리 계산해둔 document representations에 대해 빠르게 검색하기 위해 inverted index list를 활용합니다. document의 각 토큰들의 벡터에 대한 list와 COIL-full을 위한 CLS에 대한 list 두 개로 구성 되어 있습니다.
각각의 수식은 아래와 같습니다.
\[I^t = \{v_j^d | d_j = t, d \in C \}\]
\[I^{cls} = \{v_{cls}^d, d \in C \}\]
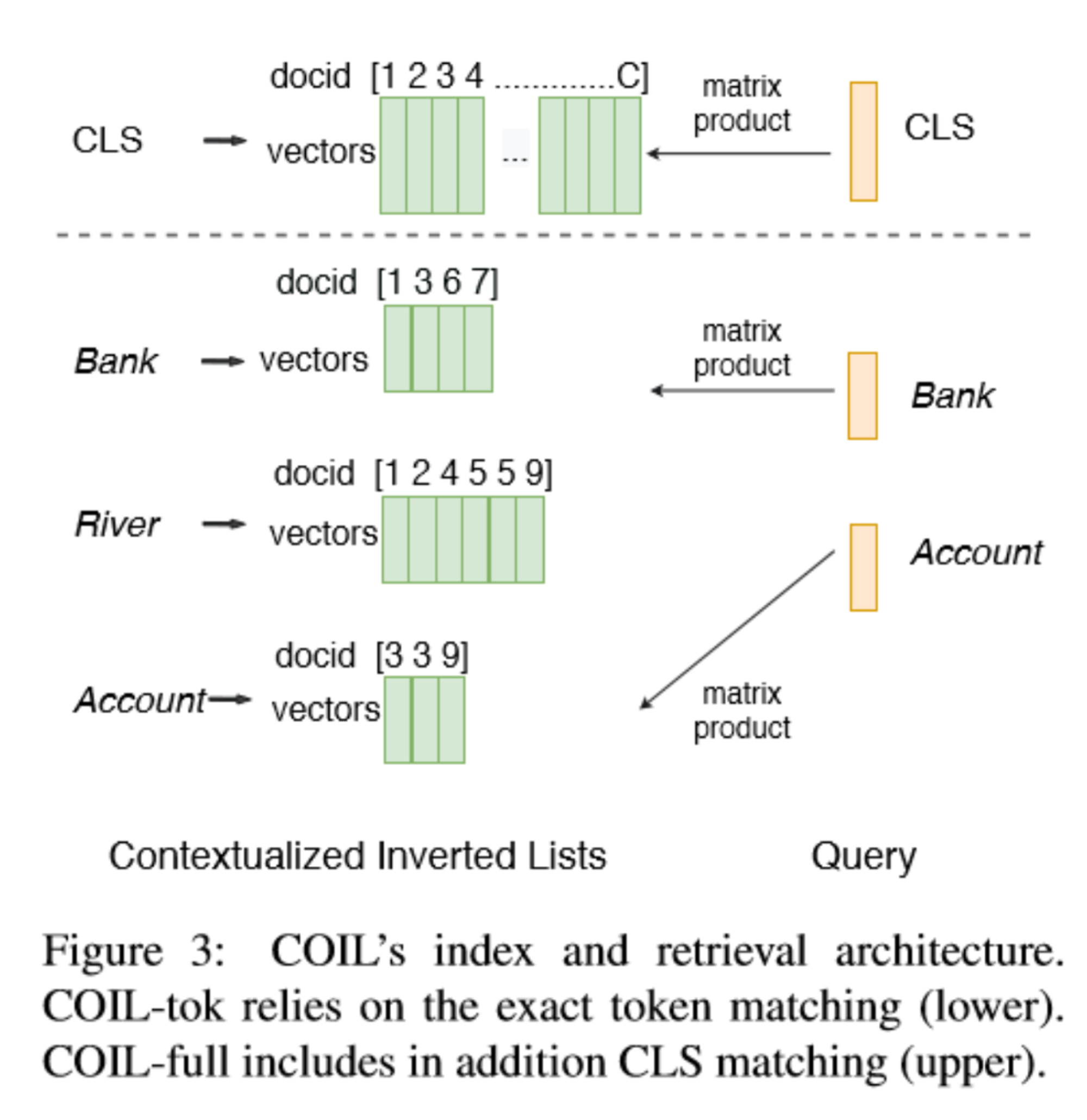
더불어 연구팀은 더욱 효율적인 시스템 구현을 위해 아래와 같은 방법을 사용했습니다.
벡터 스택 생성
각 inverted list $I^t$의 벡터를 행렬 \(M^{n_t \times |I_k|}\)로 스택 생성. 이를 통해 inverted list를 탐색하고 벡터 내적을 계산하는 작업을 최적화된 BLAS routine으로 효율적으로 처리할 수 있음. \(v_{cls}^d\)도 마찬가지로 \(M_{cls}\)로 표현할 수 있음
Approximate search index
dense vector들의 collection으로서 각 inverted list를 Approximate search index로 조직하여 검색 속도를 더욱 높일 수 있음
Parallel processing
다양한 inverted list에 대한 점수 계산은 병렬도 수행될 수 있음
Experiment & Results
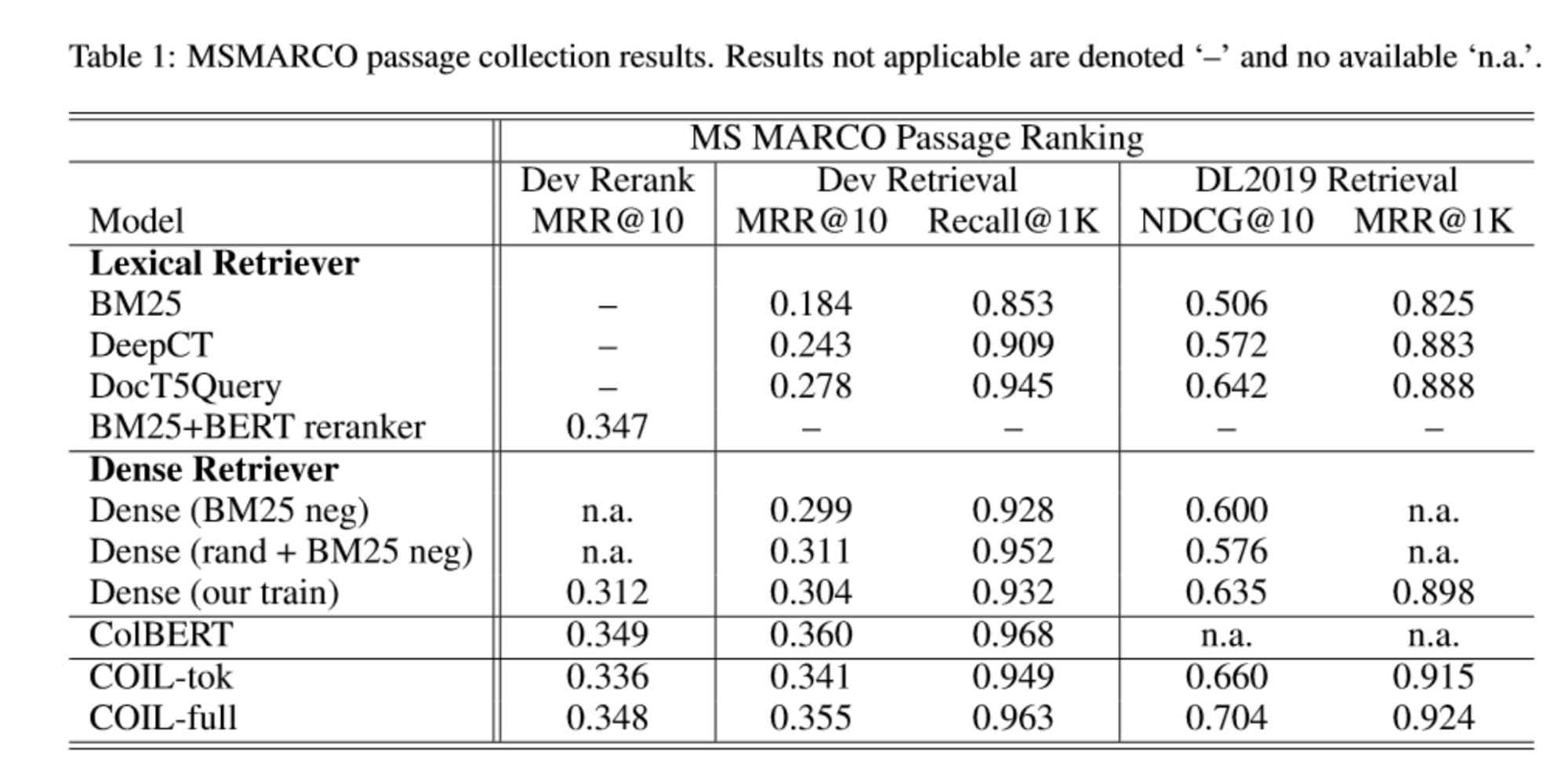
연구팀은 TREC 2019와 MSMARCO에 대해 훈련 및 평가를 진행했습니다.
결과는 다음과 같습니다.
COIL-tok와 COIL-full 시스템 모두 Lexical Retriever 보다 좋은 성능을 보여주고 있습니다. 더불어 COIL-full은 all-to-all token interation을 수행하는 ColBERT와 비교하여도 더욱 적은 연산량으로도 비슷한 성능을 보여주고 있습니다. 참고로 BERT reranker는 2700ms 이상이 소요되지만 COIL은 10ms 정도로 훨씬 빠른 속도를 보여준다고 합니다.
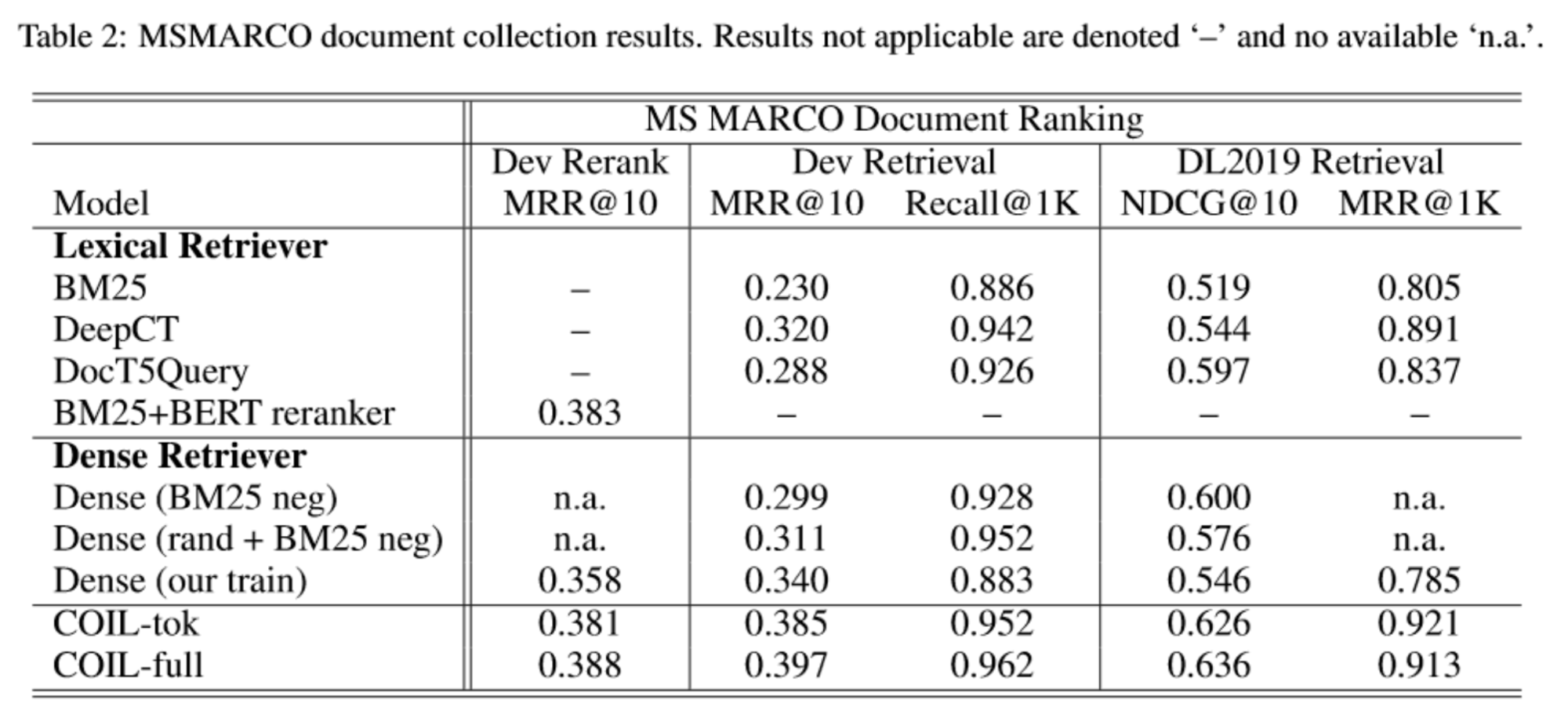
연구팀은 COIL 시스템에서 토큰 차원 \(n_t\)와 CLS 차원 \(n_c\)의 변화에 대한 성능 변화도 측정하였습니다.
결과를 살펴보면 두 토큰 차원 모두 줄여도 성능에는 큰 하락이 없는 것을 볼 수 있습니다. 이는 작은 차원으로도 충분한 성능을 유지할 수 있음을 시사한다고 합니다.
더불어 BM25와 DPR 그리고 ColBERT 모델과 Latency를 비교했을 때, COIL 모델은 낮은 차원에서도 ColBERT와 유사한 높은 성능을 보이면서 bm25와 비슷한 latency를 보이고 있습니다.
마지막으로 COIL은 기존 DPR과 같은 모델처럼 Single Embedding을 사용하여 비교하는 것이 아닌 Token-level Embedding을 비교하여 맥락 정보를 더욱 잘 파악할 수 있다고 합니다. 예를 들어 아래 Table 4의 첫 번째 쿼리에서 cabinet은 가구가 아닌 정부라는 의미로 사용이 되었는데, COIL은 이러한 맥락적 의미를 잘 포착하여 높은 점수를 부여하는 것을 확인할 수 있습니다.

Conclusion
IR 분야에서는 검색의 성능 만큼이나 효율성 (Latency, Memory Usage 등)도 매우 중요한데요, 이러한 점에서 COIL은 Exact Lexical Match 방식의 장점인 효율성과 Dense Retriver의 장점인 성능이라는 두 장점을 적절히 합친 점에서 인상적입니다.
다음 시간에는 COIL에서 static lexical routing을 개선한 CITADEL을 살펴보도록 하겠습니다.
감사합니다 😊
![[번역] The Second Half](https://images.unsplash.com/photo-1760592150404-adacb88548e2?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDJ8fHx8fHx8fDE3NjA2NTUzOTJ8&ixlib=rb-4.1.0&q=80&w=600)
![[논문 리뷰] ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS](https://images.unsplash.com/photo-1499428665502-503f6c608263?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDcyfHx8fHx8fHwxNzUyNDgwODc3fA&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 5편 (완)](https://images.unsplash.com/photo-1749225595496-06cd2c49fa2b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDZ8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 4편](https://images.unsplash.com/photo-1749221836725-494abefcd2a0?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDd8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)