[논문 리뷰] ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction
![[논문 리뷰] ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction](https://images.unsplash.com/photo-1722262179250-93e46b15f50f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDEyfHx8fHx8Mnx8MTcyMzIxOTk1OHw&ixlib=rb-4.0.3&q=80&w=960)
이번 시간에는 “ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction” 논문을 살펴봅니다.
기존 ColBERT에서는 query와 document 간의 token-level interaction과 document token 임베딩은 미리 저장해두고, inference 시에 불러와서 사용하는 late interaction을 통해 성능과 속도를 모두 챙길 수 있었는데요. 하지만 late interaction을 위해 모델의 space footprint (공간 사용량)이 10배 이상 더 쓴다는 문제점이 존재했습니다. 따라서 ColBERTv2에서는 모델의 정확도를 유지하면서 효율적인 저장 공간으로 late interaction 하는 방법에 대해 살펴봅니다.
논문은 링크에서 확인할 수 있습니다.
관련하여 아래 IR 관련 논문 리뷰들도 함께 살펴보시는 것을 추천드려요 😁
Abstract
- COlBERT와 같은 late interaction model은 model의 space footprint를 10배 이상 더 소모
- 이를 해결하기 위해 COlBertV2는 기존 ColBERT에 아래와 같은 기법을 추가
- aggresive residual compression mechanism
- denoised supervision strategy
- 다양한 벤치마크에서 SOTA 성능을 달성하면서 Late Interaction 모델의 공간 사용량을 6~10배 이상 절감
Introduction
본격적으로 시작하기에 앞서 ColBERT 모델에 대해 간략하게 살펴보겠습니다.
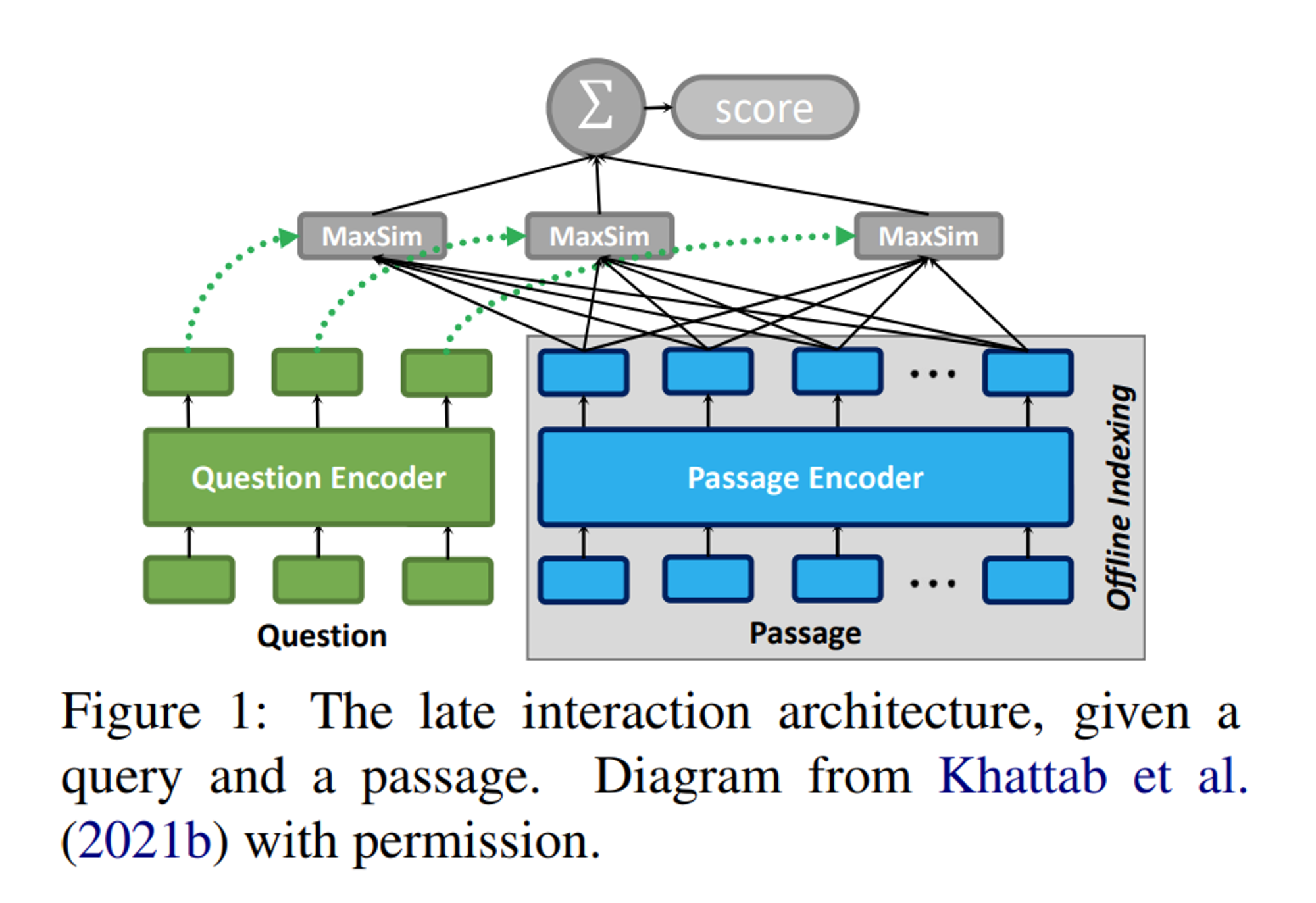
COlBERT 모델의 주요 특징은 다음과 같이 정리할 수 있습니다.
- Token-level Interaction
- 기존 Query와 Passage의 single vector를 비교하는 것이 아닌 token-level로 all-to-all interaction이 가능하여 보다 두 문장 사이의 문맥적이고, 의미적인 맥락을 잘 포착하여 성능을 높일 수 있음
- Late Interaction
- Passage의 Token Embedding 값은 미리 계산해두고 FAISS와 같은 Index에 저장해두어, Inference 시에 Retrieval만 해서 사용하면 되므로, 매번 Passage Token Embedding을 계산할 필요가 없어 Latency가 감소함.
여기서 연구팀은 기존 ColBERT에서 Late Interaction 시에 필요한 저장 공간을 문제점으로 지적하고, 이를 절감하여 Latency를 향상시키는 방법에 대해 제안합니다. 바로 살펴보겠습니다!
Approach
Modeling
우선 ColBERTv2는 기존 ColBERT의 모델의 구조를 그대로 활용합니다.
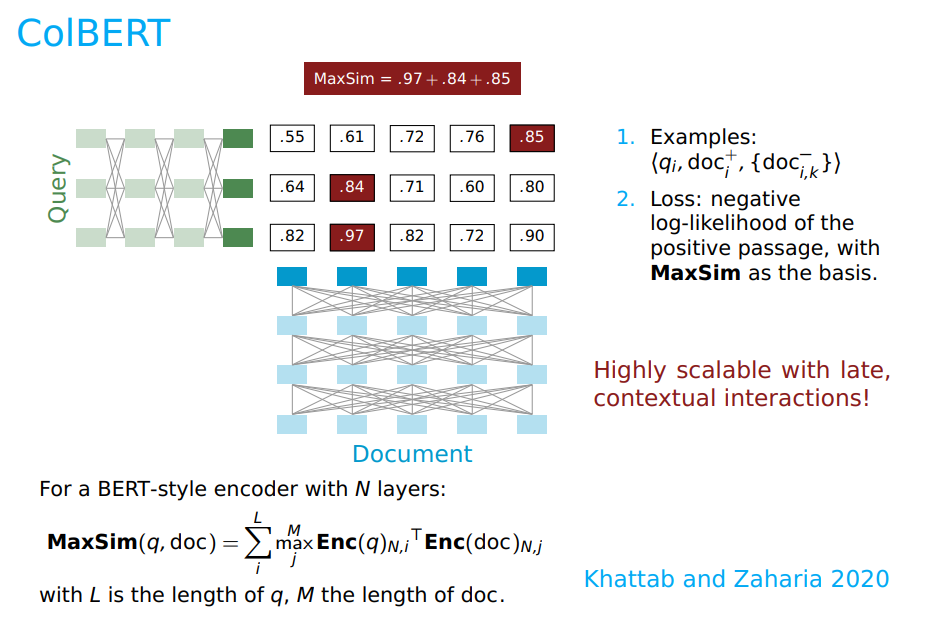
또한 기존 모델의 “MaxSim” 연산도 그대로 사용합니다.
MaxSim 연산의 핵심은 각 query 토큰 별로 가장 관련성 높은 docuemt 토큰을 찾아 점수를 합하면서, 쿼리 전체와 문서 전체의 최종 점수를 구하는 것입니다.
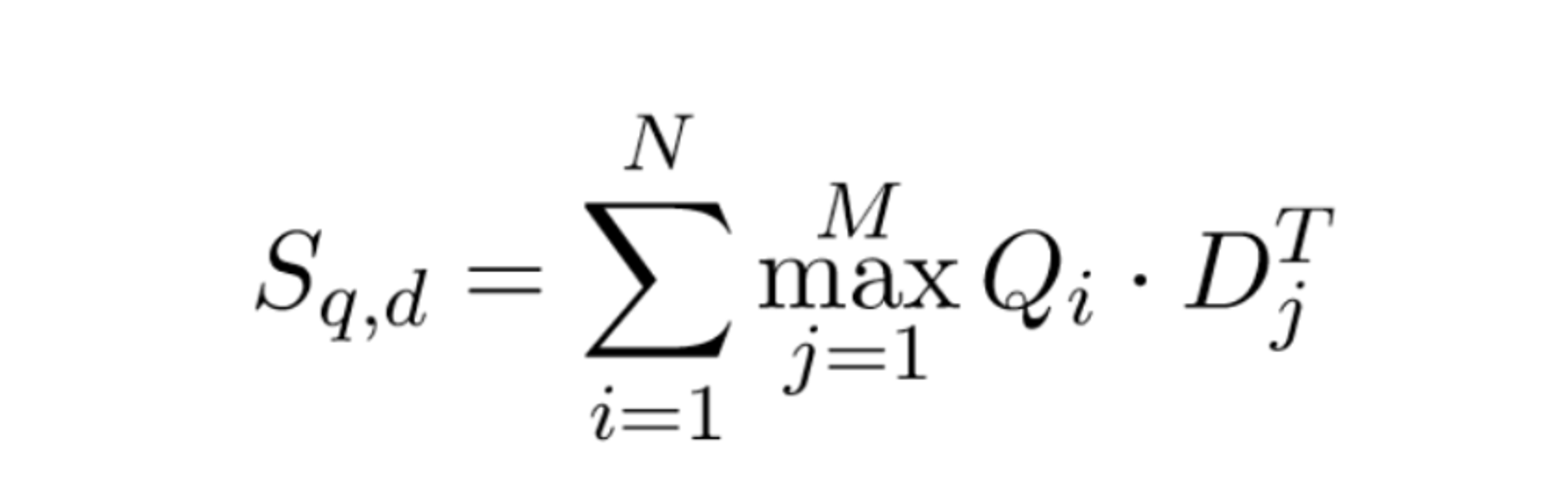
아래 강의 자료의 Figure와 함께 보시면 더욱 잘 이해됩니다!
Supervision
기존에는 Retriever를 학습하기 위해 주로 각 query (\(q\)) 별로 postive (\(d^+\))와 negative (\(d^-\)) passages의 집합을 사용했습니다. 이때 \(d^+\)는 human annotated, \(d^-\)는 unannotated 중에 BM-25 score 바탕으로 passage를 샘플링하여 선정했습니다.
하지만 기존 supervision 방법에는 더욱 어려운 negative passage를 제공하지 못하거나, 잘못된 positive 또는 negative를 제공하는 등 한계가 있어 ColBERTv2에서는 denoised supervision strategy를 제안합니다.
방법은 다음과 같습니다.
- ColBERT 모델을 사용하여 ColBERTv2 compression으로 학습 passage를 인덱싱.
- 각 학습 query에 대해 상위 k개의 passage를 검색하고, 이 query-passage 쌍을 22M MiniLM Cross Encoder reranker에 입력.
- query, 높은 순위의 passage(또는 labeled positive), 그리고 하나 이상의 낮은 순위의 passage로 구성된 w-way 튜플을 수집. (w=64)
- RocketQAv2와 유사하게, KL-Divergence loss을 사용하여 cross encoder의 점수를 ColBERT 아키텍처로 distillation.
- 이 절차를 한번 반복하여 인덱스를 refresh하고, 샘플링 된 negative passage를 갱신
이를 통해 앞서 지적한 더욱 어려운 negative passage를 제공하지 못하거나, 잘못된 positive 또는 negative를 제공하는 등 한계를 극복하여 더욱 좋은 성능을 이끌어 낼 수 있었다고 합니다.
Representation
기존 Late Interaction 모델의 주요한 문제점 중 하나인 저장 공간 문제를 해결하고자 연구팀은 aggresive residual compression mechanism을 제안합니다.
연구팀은 ColBERTv2에서 특정 토큰 의미를 가지는 벡터들끼리 클러스터링 되어 있을 것이라고 가정했습니다.
따라서 ColBERTv2는 residual representation을 활용하여 공간 효율성을 극대화합니다.
각 벡터 (\(v\)) 를 가장 가까운 Centroid (\(C_t\))의 인덱스로 인코딩하여 residual vector (\(r = v - C_t\))를 구합니다. 그리고 residual vector (\(r\))는 \(\tilde{r}\)로 근사화하여 인코딩합니다.
이때 \(\tilde{r}\)을 구하기 위해 residual vector (\(r\))의 각 차원을 1bit 또는 2bit로 quantization을 수행합니다.
이를 통해 기존 ColBERT가 16-bit precision에서 256바이트 벡터 인코딩을 사용하지만, ColBERT v2는 벡터 당 20 또는 36 바이트만을 사용하게 됩니다.
Indexing
ColBERTv2에서 인덱싱은 3가지 단계로 구성됩니다.
- Centroid Selection
우선 residual encoding과 nearest-neighbor search에 활용하기 위한 Centroid를 선택합니다.
이때 Centroid의 개수 (\(|C|\))는 코퍼스 내 \(n_{embeddings}\)의 제곱근에 비례하여 설정하는 것이 실험적으로 잘 동작했다고 합니다.
그리고 메모리 소비를 줄이기 위해 모든 Passage의 representation을 계산한 후 클러스터링하는 대신에, 컬렉션 크기의 제곱근에 비례한 passage 샘플들을 BERT로 인코딩하여 k-means 클러스터링하였습니다.
- Passage Encoding
corpus 내의 모든 passage를 선택된 centroid로 인코딩합니다. 이때 Representation 챕터에서 살펴본 것처럼 각 임베딩 별로 residual vector (\(r = v - C_t\))를 구하고 \(\tilde{r}\)로 quantization하여 인코딩을 수행합니다.
- Index Inversion
빠른 nearest-neighbor search를 지원하기 위해 각 Centroid에 해당하는 임베딩 ID들을 그룹화하고 이를 inverted list로 저장합니다. 이를 통해 검색 시에 query와 유사한 token-level 임베딩을 빠르게 찾을 수 있습니다.
Retrieval
앞선 과정으로 완성된 Index를 활용하여 검색을 수행하는 방법에 대해 살펴보겠습니다.
주어진 query의 representation Q의 각 토큰 벡터 \(Q_i\) 에 가장 가까운 Centroid를 하나 이상 찾습니다.
Inverted List를 활용하여 해당 Centroid에 가까운 passage embedding을 식별하고, decompression하여 각 query vector에 대해 cosine simirality를 계산합니다.
각 query vector에 대해 문서 ID 별로 점수를 그룹화하고, 해당 근사 점수에 기반하여 상위 n개의 후보 passage를 선택합니다.
그리고 후보 passage의 전체 임베딩을 로드하여 ColBERT MaxSim Scoring을 수행하게 됩니다.
LoTTE: Long-Tail, Cross-Domain Retrieval Evaluation
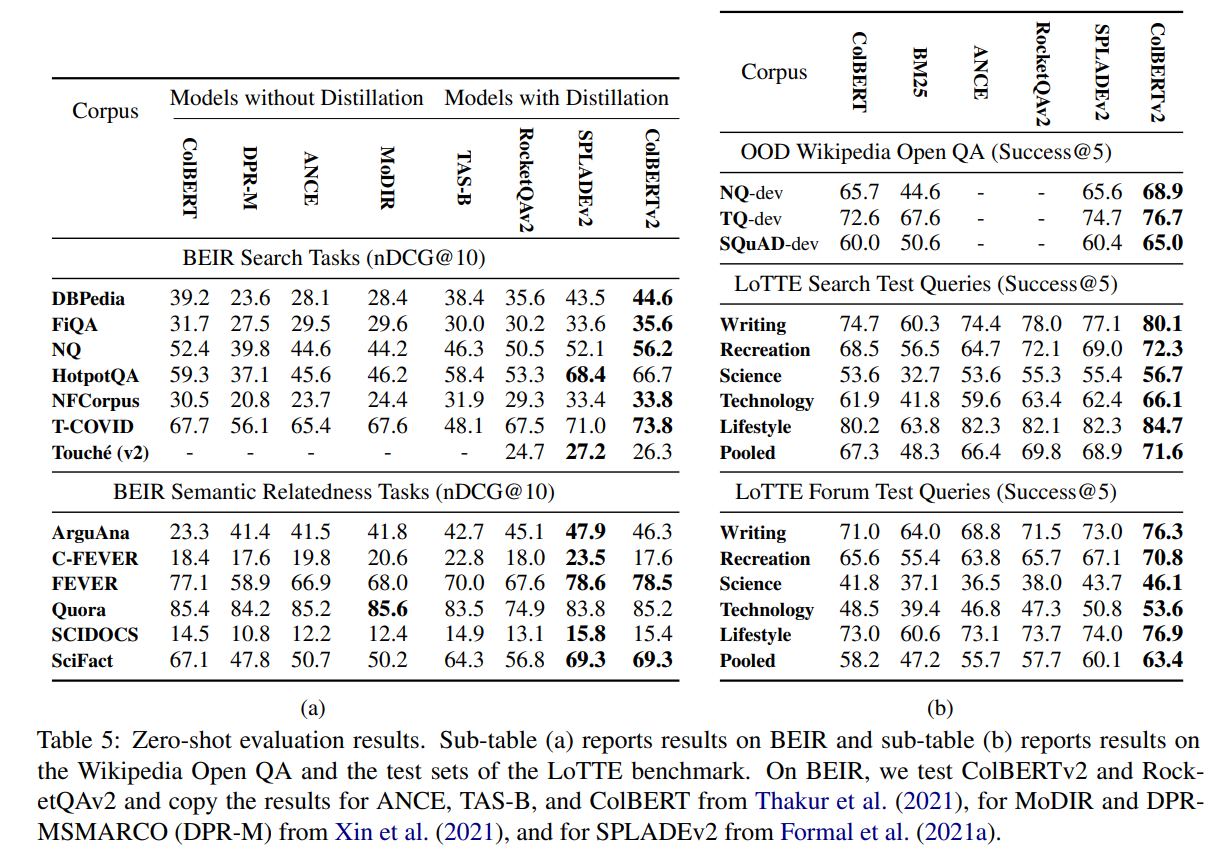
연구팀은 추가로 BEIR의 out-of-domain 테스트를 보완하기 위해 LoTTE라는 새로운 데이터셋을 제안합니다. 해당 데이터셋은 Wikipedia와 같은 Entity 중심의 지식 베이스에 포함되지 않을 수 있는 Long-tail topic에 대해 자연스러운 user query에 중점을 둡니다.
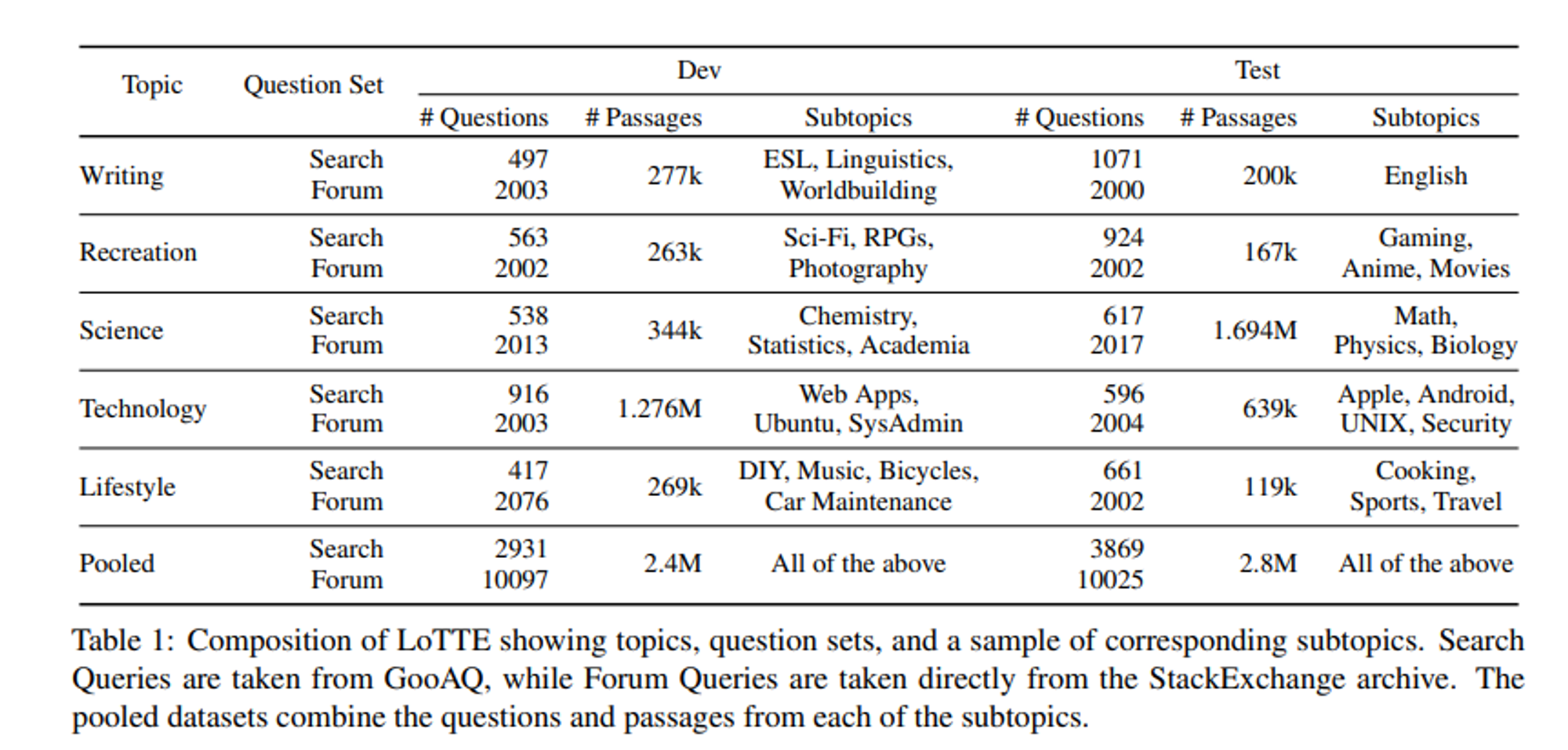
Evaluation
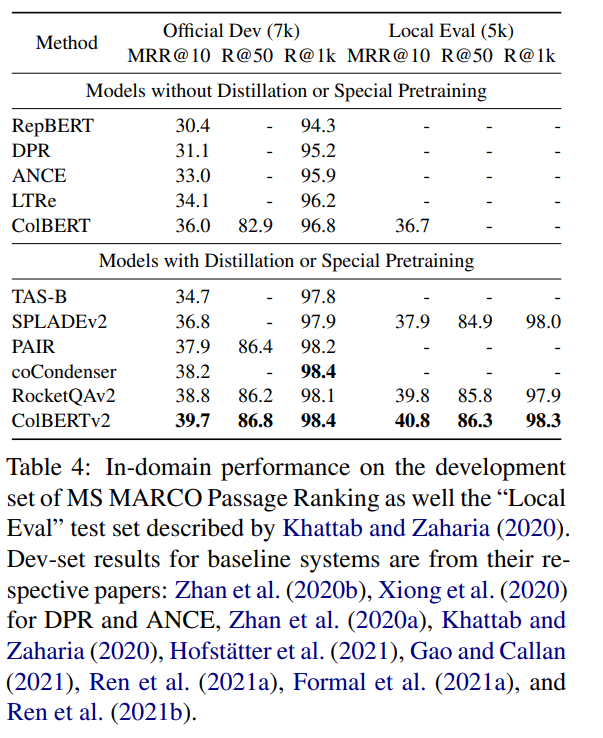
평가 결과는 다음과 같습니다. In-Domain과 Out-of-Domain 모두 인상적인 결과를 얻은 것을 볼 수 있습니다.
In-Domain Retrieval Quality
Out-of-Domain Retrieval Quality
Efficiency
- 인덱스 크기 감소
- ColBERT의 경우 MS MARCO Index를 저장하는데 154 GiB가 필요하지만, ColBERTv2는 임베딩을 차원당 1비트 또는 2비트로 압축할 때 16GiB 또는 25GiB만 필요하고, 이는 6~10배의 압축 비율을 보여줍니다. 여기에는 inverted list를 저장하는데 필요한 4.5GiB도 포함됩니다.
- Single Vector 모델과의 비교
- MS MARCO에서 Single Vector 모델의 경우 9백만 개의 passage를 각각 768차원 벡터로 4바이트 lossless floaing-point로 저장하면 25GiB가 필요합니다.
- Single vector representation도 aggresive하게 compression할 수 있지만, ColBERTv2와 같은 late interaction 모델에 비해 품질이 떨어질 수 있다고 합니다.
- Query Latency
- 쿼리 당 약 50-250 ms가 소요된다고 합니다.
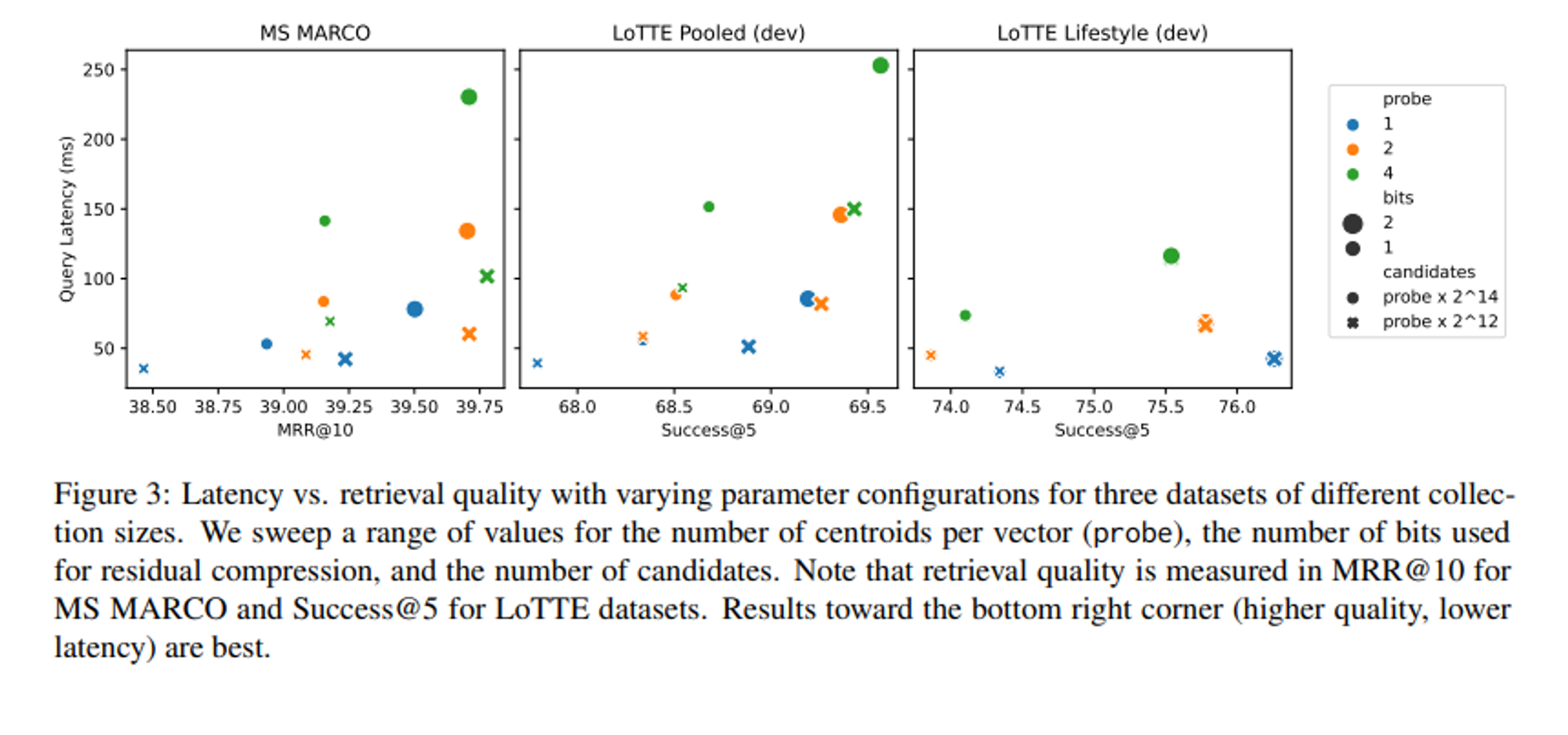
Conclusion
연구팀은 Residual Representation을 통해 저장 공간의 크기와 latency를 줄일 수 있는 ColBERTv2를 제안했습니다. 더불어 denoised supervision strategy를 통해 기존 supervision 방법을 향상시킬 수 있는 방안도 제시했습니다. 이를 통해 In-Domain과 Out-of-Domain 모두 인상적인 성능을 보여주었습니다.
감사합니다. 😁
![[논문 리뷰] ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS](https://images.unsplash.com/photo-1499428665502-503f6c608263?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDcyfHx8fHx8fHwxNzUyNDgwODc3fA&ixlib=rb-4.1.0&q=80&w=750)
![[논문 리뷰] Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning](https://images.unsplash.com/photo-1742325989789-b42912a531dd?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDN8fHx8fHx8fDE3NDI4ODc1Nzl8&ixlib=rb-4.0.3&q=80&w=750)
![[번역] The Bitter Lesson](https://images.unsplash.com/photo-1738300332814-225c81707b1b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDIxfHx8fHx8fHwxNzM5NjE5MjA1fA&ixlib=rb-4.0.3&q=80&w=750)
![[논문 리뷰] Evaluating Very Long-Term Conversational Memory of LLM Agents](https://images.unsplash.com/photo-1731332066050-47efac6e884f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDZ8fHx8fHx8fDE3MzIwMzU2MDB8&ixlib=rb-4.0.3&q=80&w=750)
![[논문 리뷰] Beyond Retrieval: Embracing Compressive Memory in Real-World Long-Term Conversations](https://images.unsplash.com/photo-1725992340772-47fd8f8df459?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDN8fHx8fHx8fDE3Mjg3MTkzNDZ8&ixlib=rb-4.0.3&q=80&w=750)
Member discussion