[논문 리뷰] ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS
![[논문 리뷰] ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS](https://images.unsplash.com/photo-1499428665502-503f6c608263?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDcyfHx8fHx8fHwxNzUyNDgwODc3fA&ixlib=rb-4.1.0&q=80&w=1200)
이번 시간에는 Image가 포함된 Document 문서를 효과적으로 Retreiving 할 수 있는 ColPali 모델을 제안한 "ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS" 논문을 리뷰합니다.
최근 텍스트뿐만 아니라 이미지, 오디오, 영상 등 multi-modal 능력을 갖춘 Foundation LM 모델들이 큰 주목을 받고 있습니다. 이와 함께 기존에는 텍스트로만 구성된 문서에서 이미지 혹은 테이블이 포함된 문서를 어떻게 잘 검색할지도 중요한 문제로 대두되고 있습니다.
기존 방식에서는 OCR 혹은 Layout Detection을 통해 이미지를 텍스트 정보로 변환한 뒤 텍스트 임베딩 모델을 활용하는 방법을 사용했지만 (예: Unstructured), 변환 과정에서의 컨텍스트 손실 및 높은 비용이 문제가 되었습니다.
그렇다면 ColPali는 기존 VLM을 활용하여 어떻게 이미지 문서 검색 문제를 해결했을까요? 한번 함께 살펴봅시다. 😊
Abstract
- 기존 문서 검색 시스템은 시각적 요소(그림, 페이지 레이아웃, 표, 글꼴 등)를 효과적으로 다루지 못함
- 문서 페이지 이미지를 직접 임베딩하여 late interaction을 통해 효율적으로 검색을 수행할 수 있는 Vision Language Model인 ColPali를 제안
- 또한 이를 평가할 수 있는 ViDoRE 벤치마크를 제안하며, ColPali는 성능, 색인 속도 및 단순성 면에서 기존 방법들을 크게 능가
Introduction
저자들은 효율적인 검색 시스템을 위해서는 세 가지 핵심 속성을 만족해야 한다고 합니다.
- R1) 강력한 검색 성능 (Strong retrieval performance)
- R2) 빠른 온라인 질의 (Fast online querying)
- R3) 높은 코퍼스 색인 처리량 (High throughput corpus indexation)
하지만 기존 Standard Retrieval System은 문서의 시각적인 요소를 효율적으로 활용하지 못하고 있다고 합니다.
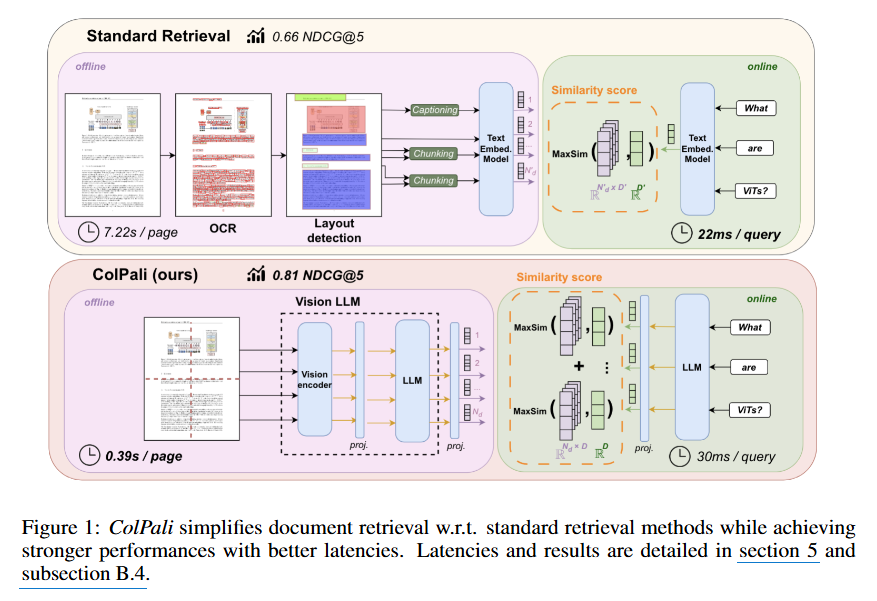
위 Figure 1을 보면 기존 방식에서는 시각적 요소가 포함된 문서를 처리하기 위해 OCR과 Layout detection과 같은 복잡한 전처리 과정을 거쳐야 하지만, 이 과정에서 R1) 검색 성능과 R3) 코퍼스 색인 처리량에서 한계를 보일 수밖에 없습니다.
또한 저자들은 기존 VLM (Vision Language Model)도 큰 발전이 있었지만 이들은 검색 작업에 특화되어 있지 않다는 점을 지적합니다.
따라서 본 연구는 문서의 시각적 특징을 직접 임베딩하여 효율적인 문서 검색을 수행할 수 있는 ColPali를 제안합니다.
The VidoRe Benchmark
본격적인 모델 소개에 앞서 연구팀은 ViDoRe (Vision Document Retrieval Benchmark)라는 새로운 벤치마크를 제안합니다.
기존 벤치마크들은 natural image (e.g., COCO, DUE, Crossmodal-3600)나 textual document (e.g., MTEB)에만 집중하고 있어 이 둘이 혼합된 Vision Document Retrieval 대한 평가가 어려웠다고 합니다.
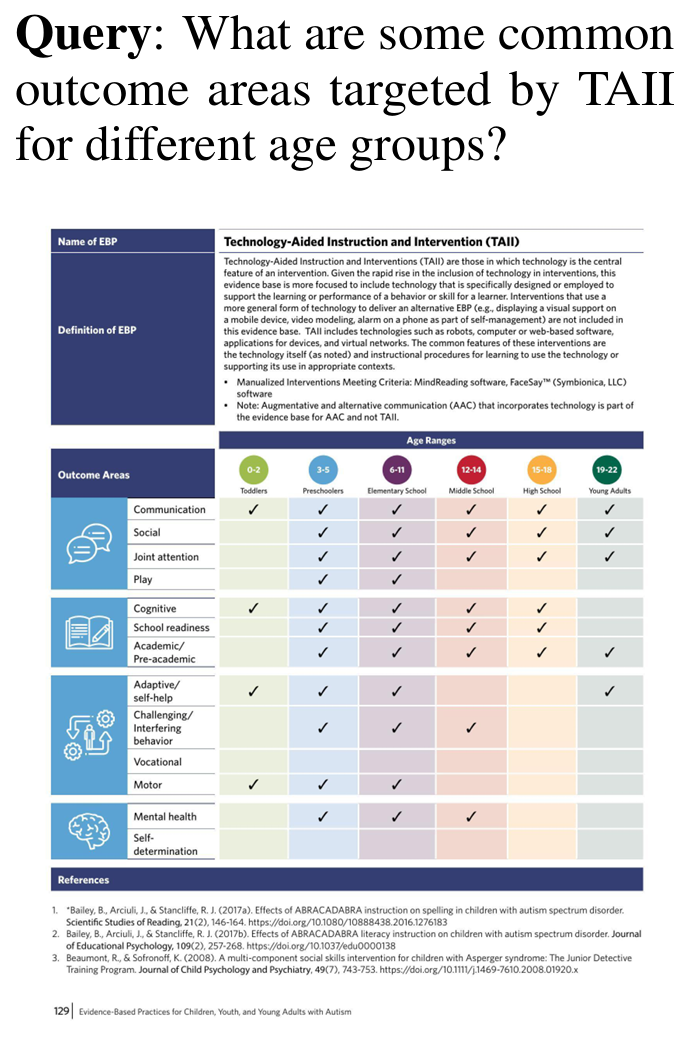
ViDoRe 벤치마크는 질의에 대해 시스템이 관련 문서 페이지를 얼마나 잘 검색하는지 페이지 수준 검색(page-level retrieval)을 평가합니다. 이때 Document는 아래 예시처럼 텍스트 뿐만 아니라 figures, infographics 그리고 tables 등을 포함합니다.
이외에도 의료(medical), 비즈니스(business), 과학(scientific), 행정(administrative) 등 여러 분야의 문서를 다루며 시스템의 성능을 세밀하게 파악하기 위해 다양한 난이도의 task를 포함한다고 합니다. 주요 평가 지표는 nDCG@K, Recall@K, MRR을 사용합니다. 또한 온라인 질의 속도 (R2)와 색인 처리량 (R3)도 평가에 포함됩니다.
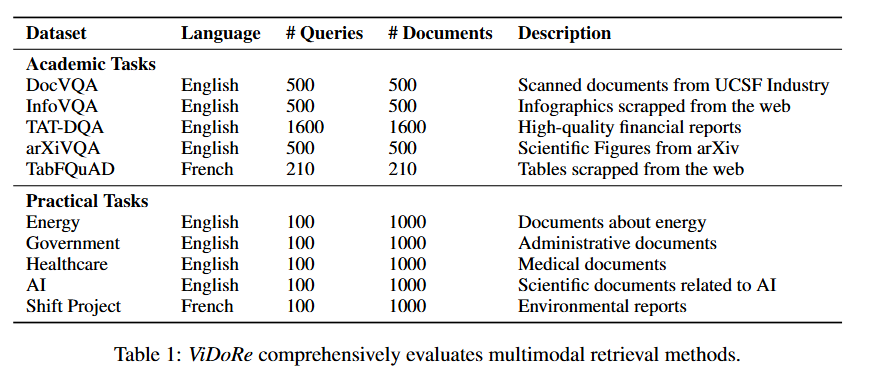
실제 VidoRe leaderboard는 아래 링크에서 확인할 수 있습니다! 현재 v2도 공개되어 있는데요, 기존 VidoRe Dataset보다 더 어렵게 만든 버전이라고 합니다.

Late Interaction Based Vision Retrieval
그렇다면 연구팀은 Vision Document Retrieval을 위한 VLM 모델을 어떻게 설계할 수 있었을까요?
ColPali는 Paligemma-3B VLM을 베이스로 하여 ColBERT와 유사하게 텍스트와 이미지에 대해 multi-vector interaction이 가능하도록 학습되었습니다.
여기서 multi-vector interaction이란 기존 방식에서는 쿼리와 문서를 각각 하나의 고정된 크기의 벡터로 표현하여 단순히 코사인 유사도 등으로 비교했습니다. 하지만 multi-vector interaction 방식에서는 토큰 레벨에서 쿼리와 문서의 임베딩 벡터들을 비교합니다. 이를 통해 보다 세밀한 토큰 레벨의 임베딩 비교 및 연산을 수행할 수 있어 검색 성능을 크게 향상시킬 수 있습니다.
자세한 내용은 아래 제 블로그 포스트를 참고해주세요 😊


ColPali의 주요 구성 요소는 다음과 같습니다. 먼저 베이스 모델로 Paligemma-3B VLM을 사용하였고, 여기에 텍스트 및 이미지 출력 토큰 임베딩을 128차원으로 투영하는 projection layer를 추가하였습니다. 입력 처리 과정에서는 문서의 경우 페이지 이미지를 패치 단위로 분할하고, 각 패치와 텍스트 토큰에 대한 임베딩 벡터를 생성합니다.
생성한 쿼리와 문서 임베딩에 대해 ColBERT와 유사한 MaxSim 기반 Late Interaction 연산을 수행합니다. 구체적으로는 각 쿼리 토큰 \(E_q^{(i)}\) 에 대해 모든 문서 토큰 \(E_d^{(j)}\) 와의 유사도를 계산하고, 그 중 최대값을 선택하여 합산하는 방식입니다.
$$LI(q, d) = \sum_{i \in \llbracket 1, N_q \rrbracket} \max_{j \in \llbracket 1, N_d \rrbracket} \langle \mathbf{E}_q^{(i)} | \mathbf{E}_d^{(j)} \rangle$$
모델 학습을 위한 손실 함수 또한 ColBERT와 유사하게 배치 내 대조 학습(Contrastive Loss)을 사용합니다. 이 손실 함수의 목표는 쿼리와 올바른 문서 페이지 쌍의 유사도 점수\(s_k^+\)는 높이고, 쿼리와 올바르지 않은 문서 페이지 쌍의 유사도 점수\(s_k^-\)는 낮추도록 모델을 학습시키는 것입니다.
$$\mathcal{L} = -\frac{1}{b} \sum_{k=1}^{b} \log \left[ \frac{\exp(s_k^+)}{\exp(s_k^+) + \exp(s_k^-)} \right] = \frac{1}{b} \sum_{k=1}^{b} \log \left( 1 + \exp(s_k^- - s_k^+) \right)$$
학습 환경은 총 118,695개의 query-document page pair를 사용하였으며, 8개의 GPU 환경에서 1 epoch, batch size 32로 진행되었습니다. 효율적인 fine-tuning을 위해 LoRA 기법을 활용했습니다.
Results
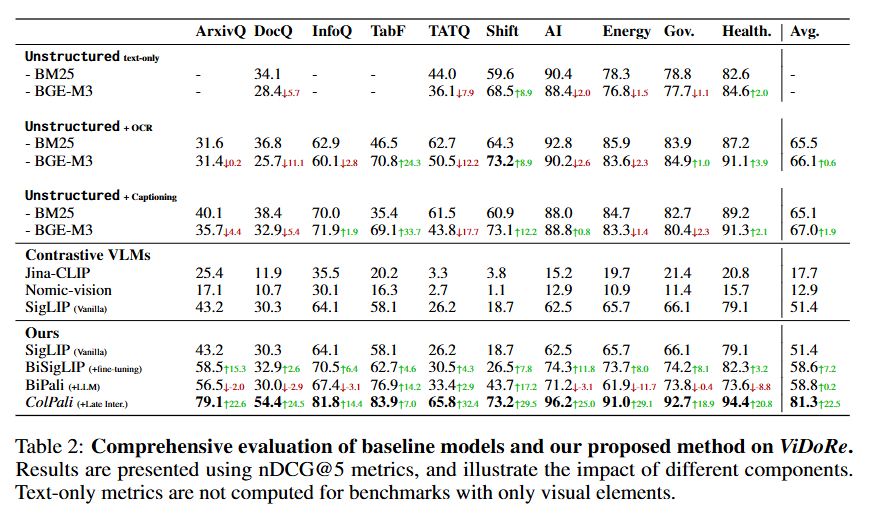
모델 성능 비교 결과는 아래와 같습니다. 총 5가지 종류의 모델을 비교-평가 하였습니다.
- Unstructured: 텍스트 정보만 사용. 이때 이미지 파싱을 위해 Unstructured 라이브러리 활용.
- Unstructured + OCR: OCR을 통해 이미지, 표, 차트의 텍스트를 추출하여 추가한 버전
- Unstructured + Captioning: Claude-3 Sonnet과 같은 강력한 VLM으로 시각적 요소에 대한 상세한 설명을 생성하여 추가
- Contrastive VLM: Jina-CLIP, Nomic-vision, SigLIP (Vanilla)와 같이 이미지와 텍스트를 독립적으로 임베딩하는 bi-encoder 모델
- ColPali: 제안한 시스템으로 BiSigLIP (+fine-tuning)은 문서 검색 데이터셋으로 SigLIP의 텍스트 컴포넌트를 fine-tuning한 모델, BiPali (+LLM)은 SigLIP 패치 임베딩을 Gemma-2B LLM에 입력하여 단일 벡터로 표현하는 bi-encoder 모델
당연하게도 (?) 제안한 ColPali (+Late Inter.) 모델이 가장 높은 성능을 보여주고 있습니다. 시사하는 바는 아래와 같습니다.
- 시각적 정보가 중요한 Task (ArxivQ, InfoQ, TabF)에서 Text-based method (Unstructued)는 큰 한계를 보임
- OCR 혹은 Captionaing은 Text-based method의 성능을 향상시킬 수 있지만 부수적인 리소스와 latency를 발생시킴
- Contrastive VLM 모델은 대체로 낮은 성능을 보이고 있는데 이는 단순 VLM은 문서 검색 task에 최적화되지 않았음을 시사함.
- ColPali (+Late Inter.)는 다양한 Task에서 높은 성능을 보이고 있는데 VLM과 Late Interaction을 활용하는 방식이 Vision Document Retriever에 효과적임을 시사함. 더불어 텍스트 중심 문서에서도 효과적인 성능을 달성함
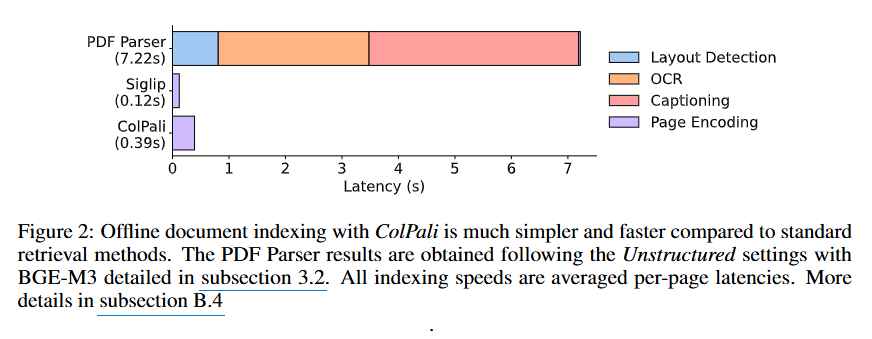
온라인 질의 응답 속도(Online Querying - R2) 측면에서 BGE-M3는 15개 토큰 인코딩에 약 22ms가 걸리는 반면, ColPali는 질의 인코딩에 약 30ms가 소요됩니다. 이는 근소한 차이로 실용적 수준을 유지하고 있다고 볼 수 있습니다. 오프라인 색인 처리량(Offline Indexing - R3) 측면에서는 더욱 인상적인 결과를 보여줍니다. PDF 파싱 방식이 복잡한 전처리로 인해 높은 지연시간을 보이는 반면, ColPali는 직접 인코딩과 배치 처리가 가능하므로 훨씬 효율적입니다.
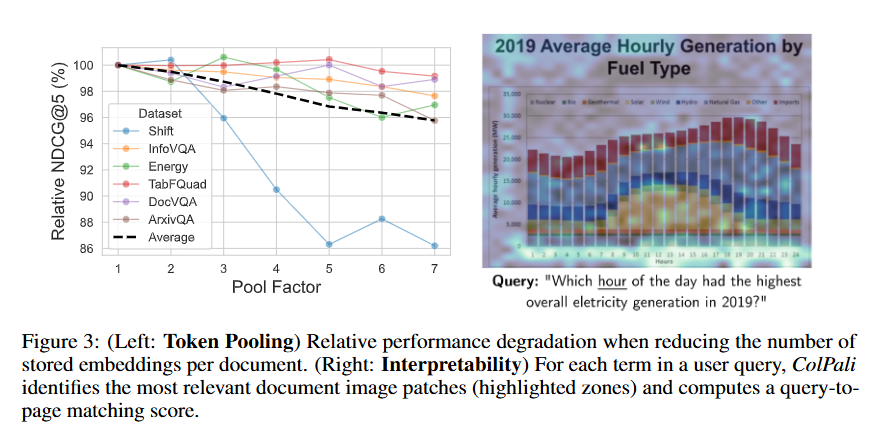
추가적으로 ColPali는 성능뿐만 아니라 Interpretability 측면에서도 큰 이점을 제공하는데요, 아래 그림은 쿼리에 대해 모델이 문서 페이지의 어떤 요소에 집중하고 있는지 히트맵으로 시각화한 결과입니다.
주목할 점은 "hourly"와 "hours" 단어에 대한 정확한 OCR 능력을 보여준다는 것입니다. 또한 Hours 축과 같은 중요한 시각적 정보에 대해 적절한 attention을 하고 있으며, Hours 축(x-axis) 등 의미론적으로 관련된 시각적 요소까지 포착하고 있습니다.
Ablation Study
이외에도 연구팀은 다양한 Abaltion Study를 진행하였는데요, 요약하면 다음과 같습니다.
- Tradeoffs between model size and the number of image patches
- Vision Language Model (VLM)의 크기(예: PaliGemma 512 패치 vs 1024 패치, ColIdefics2 64 패치)와 입력으로 사용되는 이미지 패치 수가 성능 및 효율성에 미치는 영향을 탐구
- 이미지 패치 수가 적을수록 메모리 사용량은 줄지만 성능 저하가 발생할 수 있음
- Unfreezing the vision component
- 모델 학습 시 비전 인코더를 함께 업데이트 할 때 약간의 성능 저하가 발생한다고 합니다.
- Impact of “query augmentation” tokens
- ColBERT 방식에서 사용되는 5개의 <unused0> 토큰을 쿼리 뒤에 붙이는 방식은 영어 벤치마크에서는 유의미한 성능 차이가 없었지만, 프랑스어 Task (Shift, TabFQuAD)에서는 성능 향상이 있었다고 합니다
- Impact of the Pairwise CE loss
- 가장 어려운 네거티브 샘플만 고려하는 pairwise CE loss 대신, 배치 내 모든 네거티브 샘플을 고려하는 contrastive loss를 사용하였을 때 약간의 성능 저하가 관찰되었다고 합니다.
- Adapting models to new tasks
- 소량의 특정 도메인/언어 데이터(프랑스어 표)를 학습 데이터에 추가하는 것만으로도 해당 작업(TabFQuAD)에서 명확한 성능 향상을 보였으며, 다른 작업에서는 성능 저하가 없었음
- Better VLMs lead to better visual retriever
- 더 뛰어난 VLM(Qwen2-VL 2B)를 사용 했을 때 더 나은 검색 성능을 보였으며 이는 생성 작업에서의 VLM 성능이 검색 성능과 상관관계가 있음을 시사
- Out-of-domain generalization
- ViDoRe 벤치마크와 완전히 독립된 데이터셋(DocMatix)으로만 ColPali를 학습시킨 후 ViDoRe에서의 성능을 평가 했을 때 성능 저하가 미미함
- 이는 학습 데이터 외의 데이터에 대해서도 잘 일반화됨을 입증
Conclusions
본 연구는 시각적으로 복잡한 문서가 포함되었을 때 검색 성능을 평가할 수 있는 벤치마크인 ViDoRe를 제안하고, 이를 효과적으로 처리할 수 있는 모델인 ColPali를 제안합니다. ColPali는 ColBERT 컨셉과 유사하게 문서를 이미지로 입력받아 토큰 레벨로 Late Interaction을 수행하여 높은 검색 성능을 보일 뿐만 아니라 효율성 측면에서도 상당한 이점을 보입니다.
향후 연구로는 ColBERT에서도 제기되었던 token-level interaction의 한계들인 메모리 혹은 인덱싱 이슈 등에 대한 해결책 연구나 다른 task 및 언어에 대한 robustness 등 흥미로운 후속 실험들이 가능할 것으로 생각됩니다.
최근 모델의 Multi-modality 성능이 중요해지고 있는 상황에서, 검색 분야에서도 같은 관심이 집중되는 것이 흥미롭습니다. 실제로 real-world의 문서는 다양한 이미지, 그림, 레이아웃으로 구성되어 있는 만큼 해당 기법의 가능성은 무궁무진하다고 생각됩니다.
이상으로 ColPali 논문 리뷰를 마무리합니다.
감사합니다 😊
![[번역] The Second Half](https://images.unsplash.com/photo-1760592150404-adacb88548e2?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDJ8fHx8fHx8fDE3NjA2NTUzOTJ8&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 5편 (완)](https://images.unsplash.com/photo-1749225595496-06cd2c49fa2b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDZ8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 4편](https://images.unsplash.com/photo-1749221836725-494abefcd2a0?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDd8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 3편](https://images.unsplash.com/photo-1748452944022-6212ec36a45d?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDJ8fHx8fHx8fDE3NDkyMTczOTN8&ixlib=rb-4.1.0&q=80&w=600)