[논문 리뷰] Evaluating Very Long-Term Conversational Memory of LLM Agents
![[논문 리뷰] Evaluating Very Long-Term Conversational Memory of LLM Agents](https://images.unsplash.com/photo-1731332066050-47efac6e884f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDZ8fHx8fHx8fDE3MzIwMzU2MDB8&ixlib=rb-4.0.3&q=80&w=1200)
들어가며
이번 시간에는 Evaluating Very Long-Term Conversational Memory of LLM Agents 논문에 대해 살펴봅니다.
최근에 ChatGPT를 필두로 사람과 LLM 간의 대화가 활발해지면서, LLM Agent가 사용자와 그동안 했던 대화를 기억(Memory)하고 답변에 적재적소로 활용할 수 있는 능력 또한 중요해지고 있습니다.
하지만 기존의 데이터셋은 대화 세션의 길이가 충분히 길지 않아, 긴 대화 속에서의 LLM의 기억 및 답변 생성 능력을 평가하기에 제한적이었습니다. 따라서 본 논문은 매우 긴 대화 속에서 LLM의 기억 및 대화 생성 능력을 평가할 수 있는 LOCOMO라는 데이터셋을 제안합니다. 함께 자세히 살펴봅시다 😊
 Adyasha Maharana
Adyasha Maharana
Abstract
- 기존의 Long-Term open-domain dialogues는 대화 세션이 5개 이하인 짧은 맥락에서만 모델 응답을 평가하는데 중점을 둠
- 하지만 매우 긴 대화 상황 속에서의 RAG와 LLM의 효능은 아직 탐구 되지 않았음
- 따라서 35세션에 걸쳐 평균 300턴, 9K 토큰으로 구성된 대화 데이터 세트인 LOCOMO를 제안
- LLM 기반 에이전트 아키텍처와 persona와 temporal event graph에 기반한 대화를 생성하기 위한 human-machine pipeline을 통해 고품질의 매우 긴 대화를 생성하고 평가할 수 있었음
- 질문 응답, 사건 요약, 다중 모달 대화 생성 작업 등을 포함하며, 모델들이 긴 대화에서 정보를 이해하는 능력을 평가하는 데 중점을 두고 있음
- LLM은 아직 긴 대화를 이해하고 복잡한 시간적 및 인과적 관계를 이해하는데 어려움을 겪고 있으며, long-context LLM과 RAG와 같은 전략들을 통해 개선할 수 있지만 아직 인간 성능에 미치지 못함
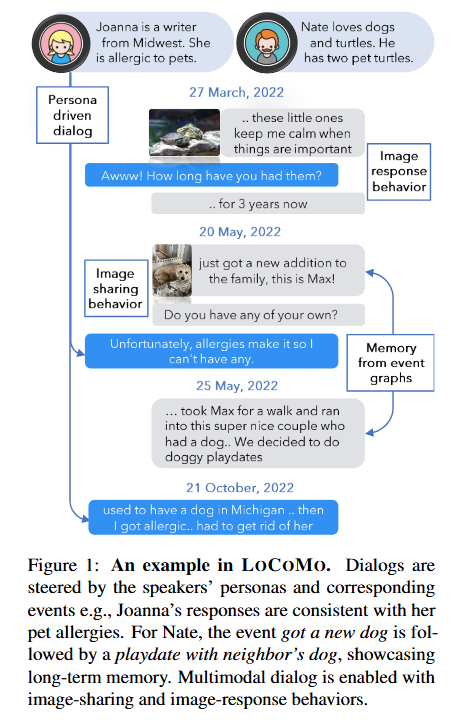
Introduction
최근 들어 다양한 LLM(대규모 언어 모델) 기반 대화 모델들이 빠르게 발전하고 있습니다. 대화가 길어질수록 모델이 이전 상호작용에서 중요한 정보를 기억하고 이를 바탕으로 공감적이며 일관성 있는 답변을 생성하는 능력이 점점 더 중요해지고 있습니다. 이러한 능력은 특히 긴 대화(long-term conversation)를 처리하는 데 중요합니다.
하지만 Table 1에서 확인할 수 있듯이 기존 데이터셋들은 최대 5개의 세션(약 1000 토큰)에 해당하는 대화를 기반으로 평가를 진행하는 등, 대화 모델이 긴 대화 맥락을 잘 처리하는지 평가하는데 한계가 있습니다.
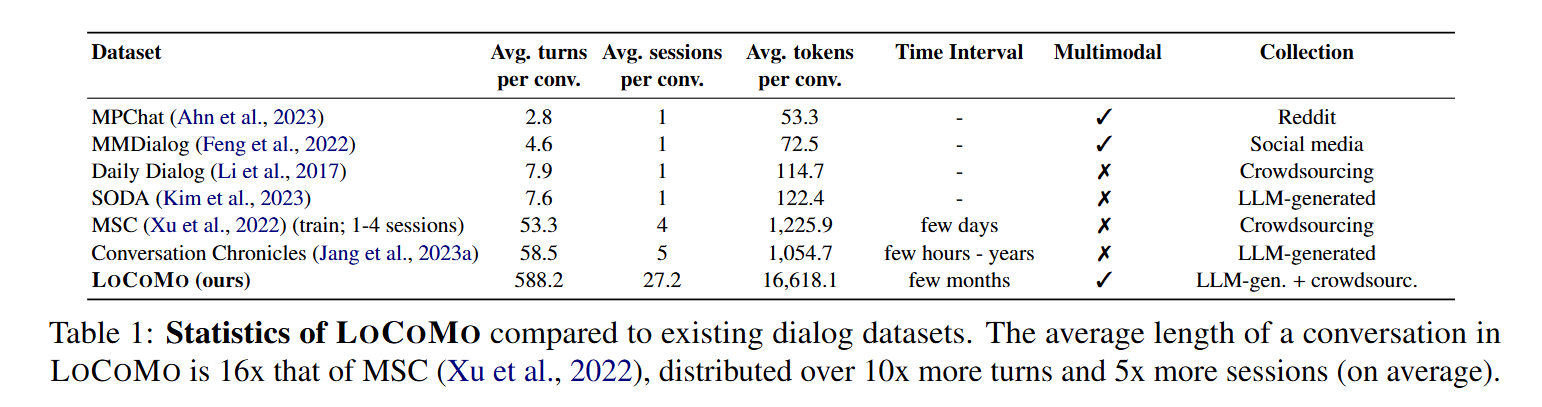
따라서 연구팀은 기존 데이터셋 대비 평균 16배 더 긴 대화, 10배 더 많은 턴, 그리고 5배 더 많은 세션을 포함하는 LOCOMO를 제안합니다.
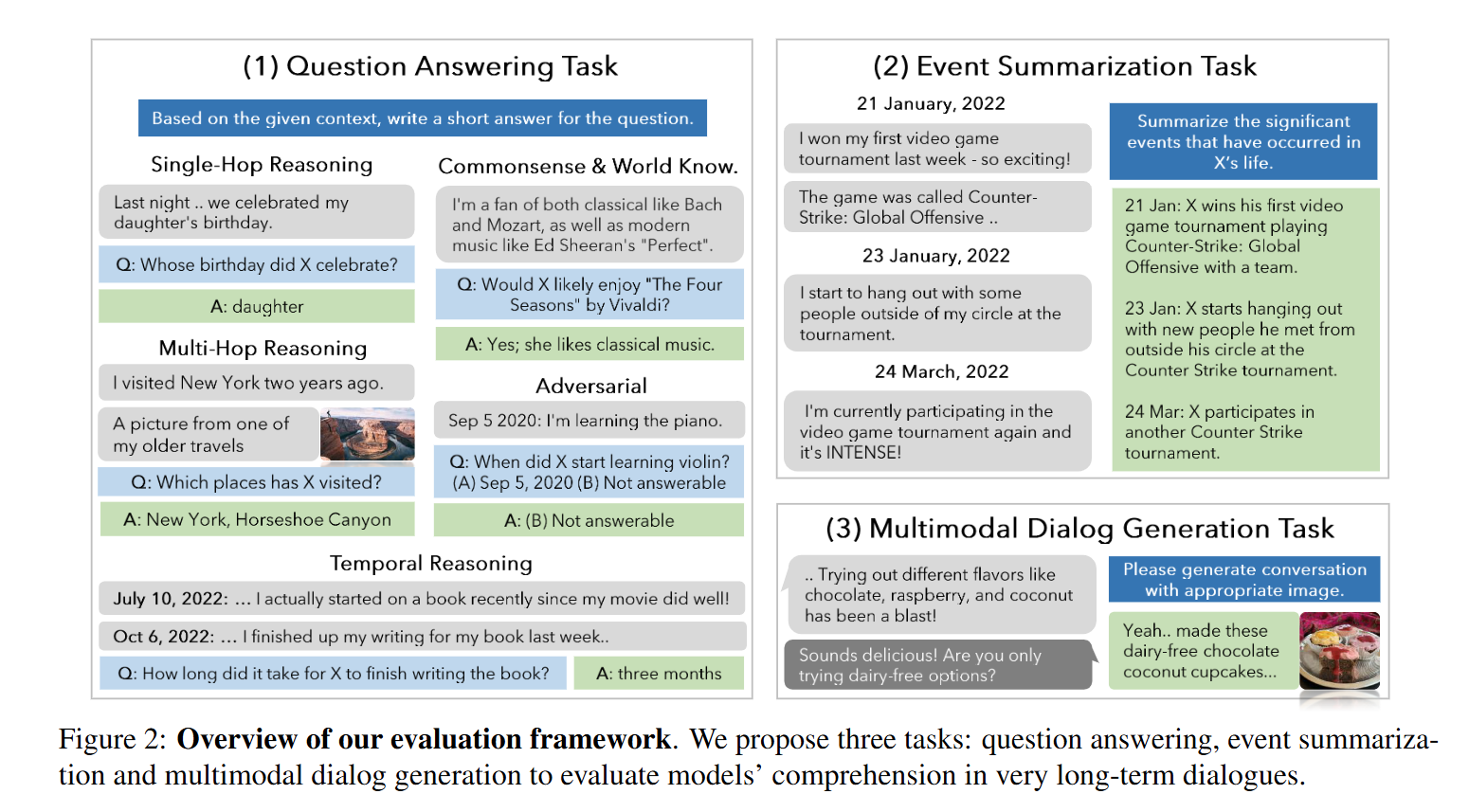
본 데이터셋은 크게 3가지의 평가 task로 구성되어 있습니다.
- Question Answering Task
- 모델이 과거 대화 맥락을 기억하고 이를 활용하여 질문에 응답할 수 있는 능력을 측정하며, 5 개의 sub-task로 구성됨.
- Single-hop Reasoning: 한 세션 내에서 답변이 가능합니다.
- Multi-hop Reasoning: 여러 세션에서 정보를 조합하여 답변해야 합니다.
- Temporal Reasoning: 시간 관련 데이터를 분석하여 답변합니다.
- Commonsense or world knowledge: 외부 지식과 함께 제공된 정보를 결합하여 답변합니다.
- Adversarial: 에이전트를 유도하여 잘못된 답변을 하도록 하는 질문입니다. 에이전트는 이러한 질문을 알아차리고 대답하지 않아야 합니다.
- 모델이 과거 대화 맥락을 기억하고 이를 활용하여 질문에 응답할 수 있는 능력을 측정하며, 5 개의 sub-task로 구성됨.
- Event Summarization Task
- 대화 속의 시간적 및 인과적 연결을 인식하여 모델이 공감하는 응답을 생성할 수 있는지를 평가
- Multimodal Dialog Generation Task
- Multimodal Dialog에서도 Ground Truth Reponse를 일치하게 생성하는지 평가
Generative Pipeline for LOCOMO
그렇다면 연구팀은 어떻게 LOCOMO 데이터셋을 만들 수 있었을까요?
- Persona
우선 두 개의 가상 에이전트 L1과 L2를 생성합니다. 그리고 각 에이전트에 Persona가 할당됩니다. 이때 할당할 Persona는 MSC Dataset에서 선택하여 사용합니다.
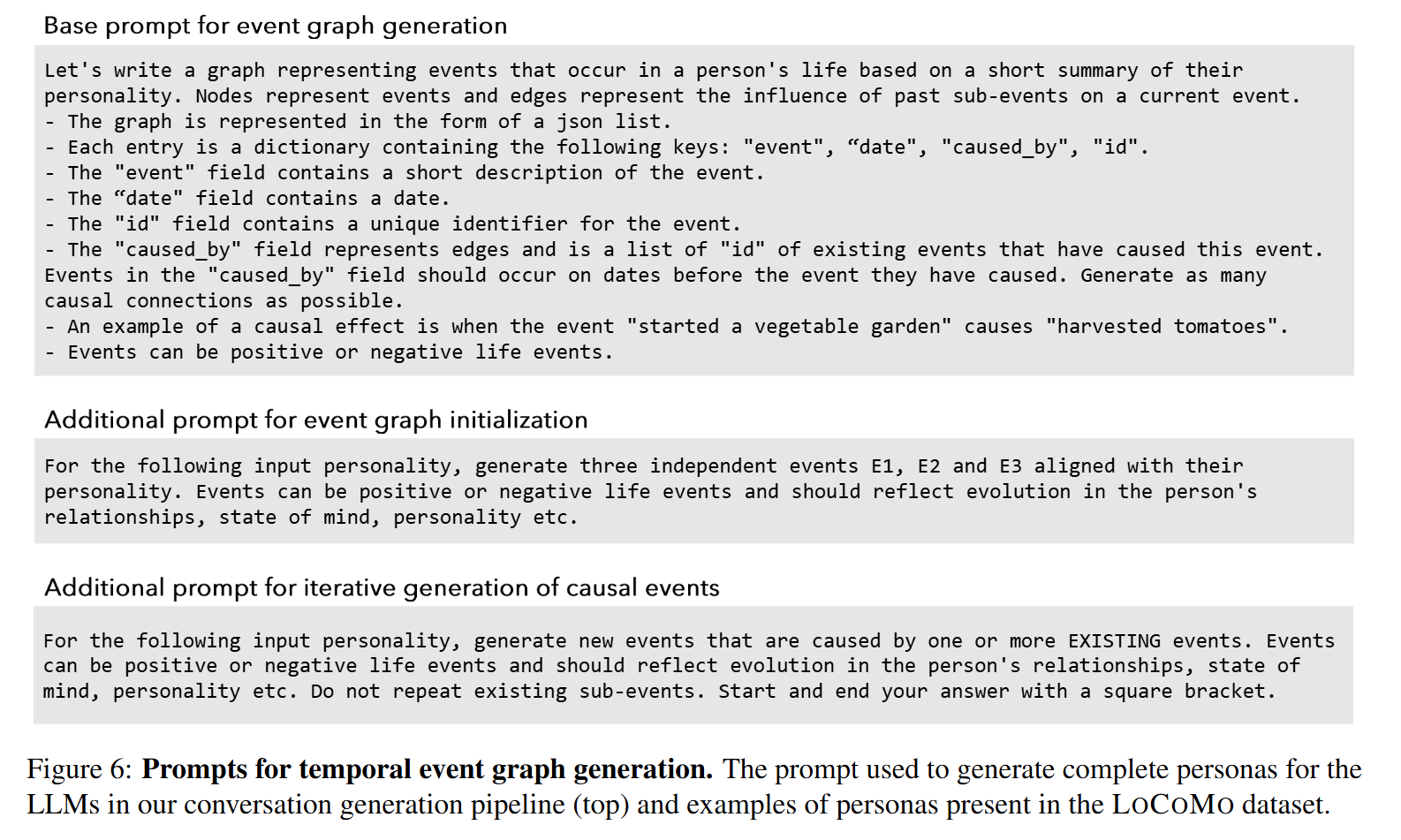
- Temporal Event Graph
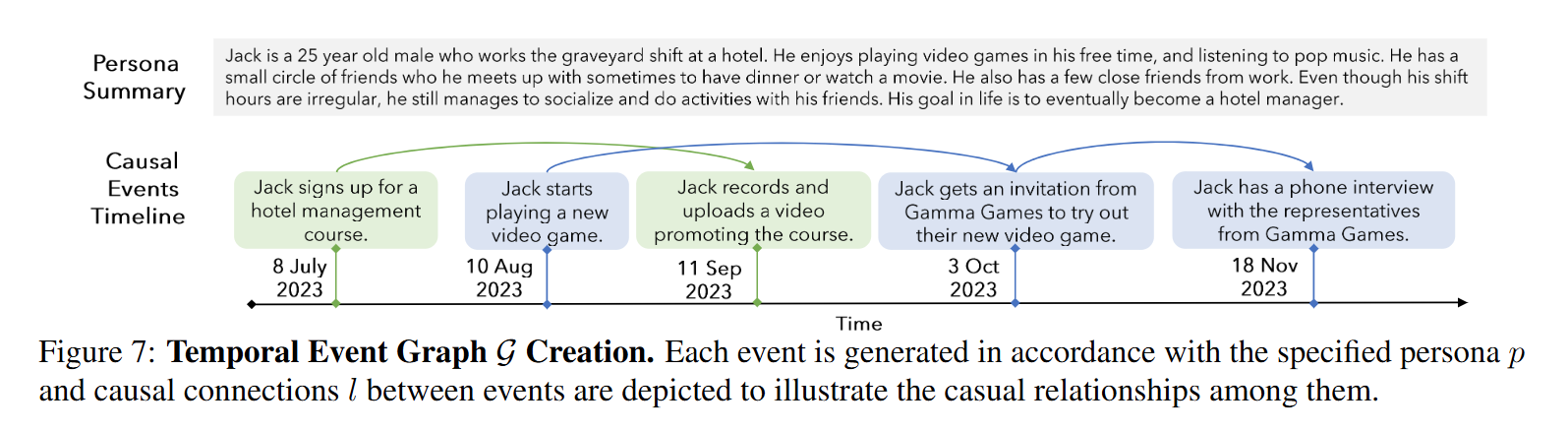
그리고 각 Agent에 대해 Temporal Event Graph (G)를 만듭니다.
해당 그래프는 사건들 \(e_i\) 로 구성되며, 각 사건은 발생 일자 \(t_i\)와 연결됩니다. 그리고 사건 간의 인과 관계 \(I = (e_i, e_j)\)를 통해 사건들의 자연스러운 순서를 반영합니다. 보통 6개월에서 1년의 시간 프레임에 걸쳐 최대 25개의 사건이 생성됩니다. 이를 통해 에이전트의 대화에서 인물의 개인적 경험과 그들 간의 인과관계를 나타낼 수 있다고 합니다. 생성 프롬프트는 아래와 같습니다.
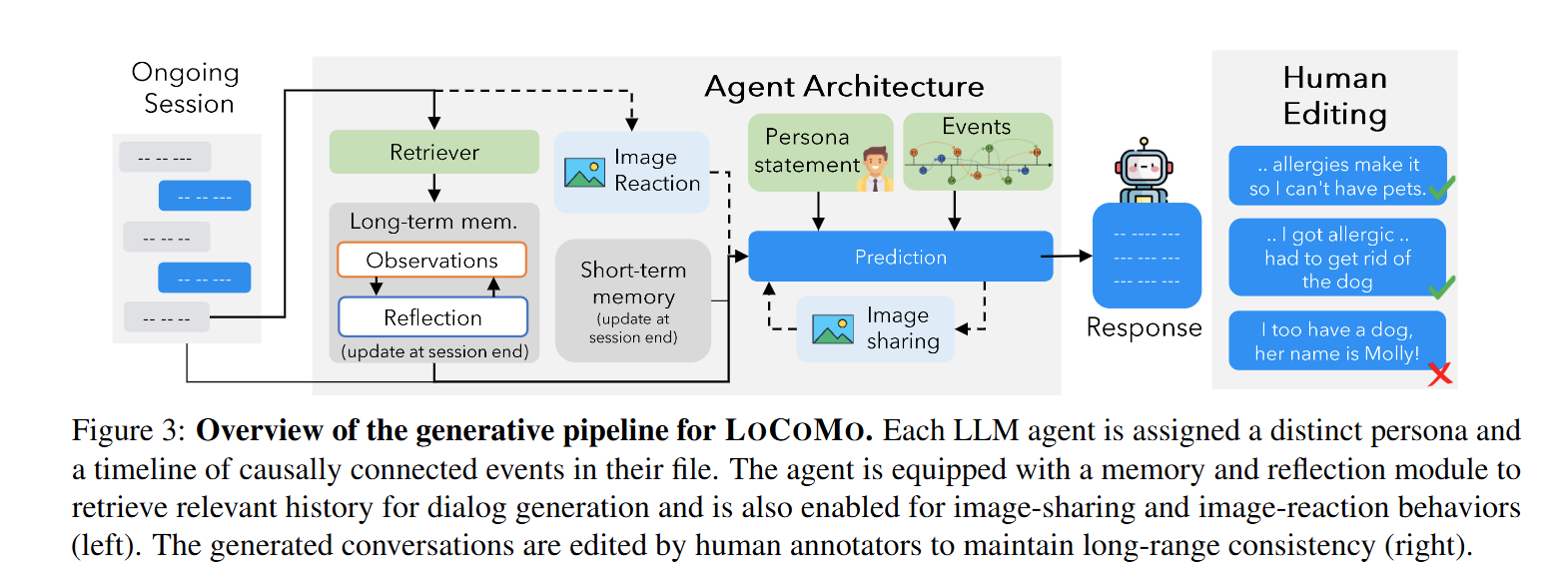
- Virtual Agent Architecture
각 에이전트는 (1) reflect & response 그리고 (2) image sharing & image reaction 모듈을 가지고 있습니다.
(1) reflect & response: short-term memory와 long-term memory를 활용하여 이전 대화 내용을 기억하고, 이를 바탕으로 대화를 생성할 수 있습니다.
(2) Image sharing & image reaction: 대화 중 에이전트가 이미지를 공유하거나, 다른 에이전트로부터 이미지를 받았을 때 반응을 생성할 수 있습니다.
- Human Verification & Editing
마지막으로 생성된 대화는 Human Annotator에 의해 수동으로 검토되고, 장기 일관성을 유지하기 위해 editing 될 수 있다고 합니다.
위와 같은 과정을 통해 LOCOMO는 높은 품질의 아주 긴 대화를 생성할 수 있었습ㄴ디ㅏ.
Experimental Results
LOCOMO를 통해 아래 3가지 모델 군을 평가하였습니다.
- Base LLMs (Ex. Mistral-Instruct-7B, Llama-2-Chat-70B ...)
- Long Context LLMs (Ex. GPT-3.5-turbo-16K)
- RAG models
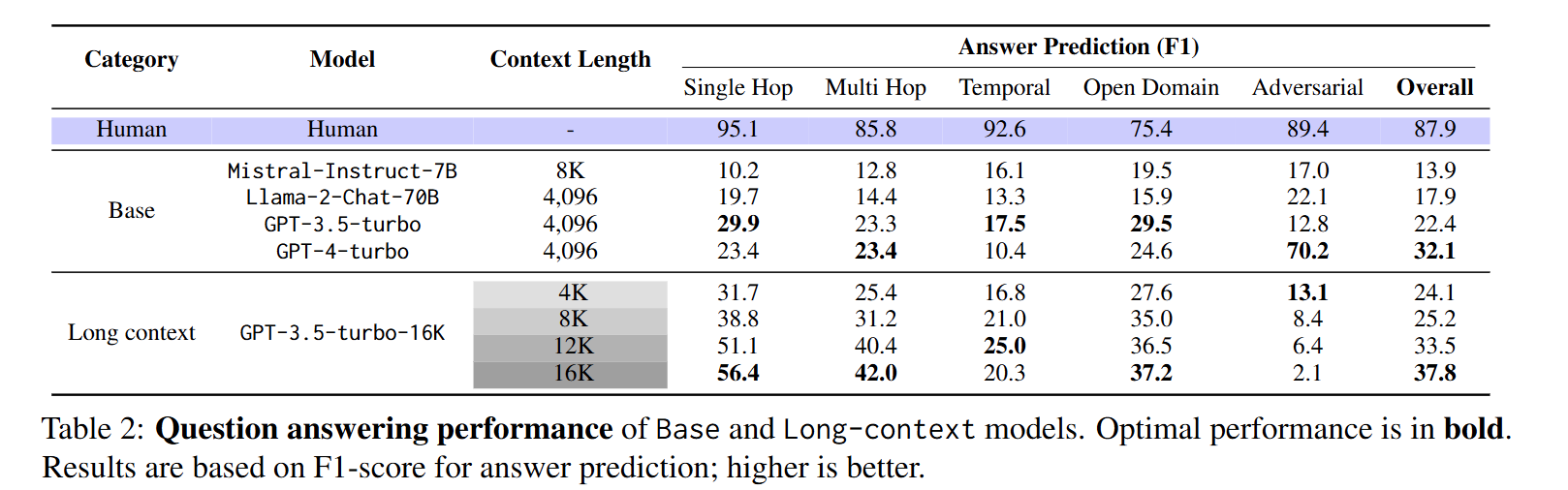
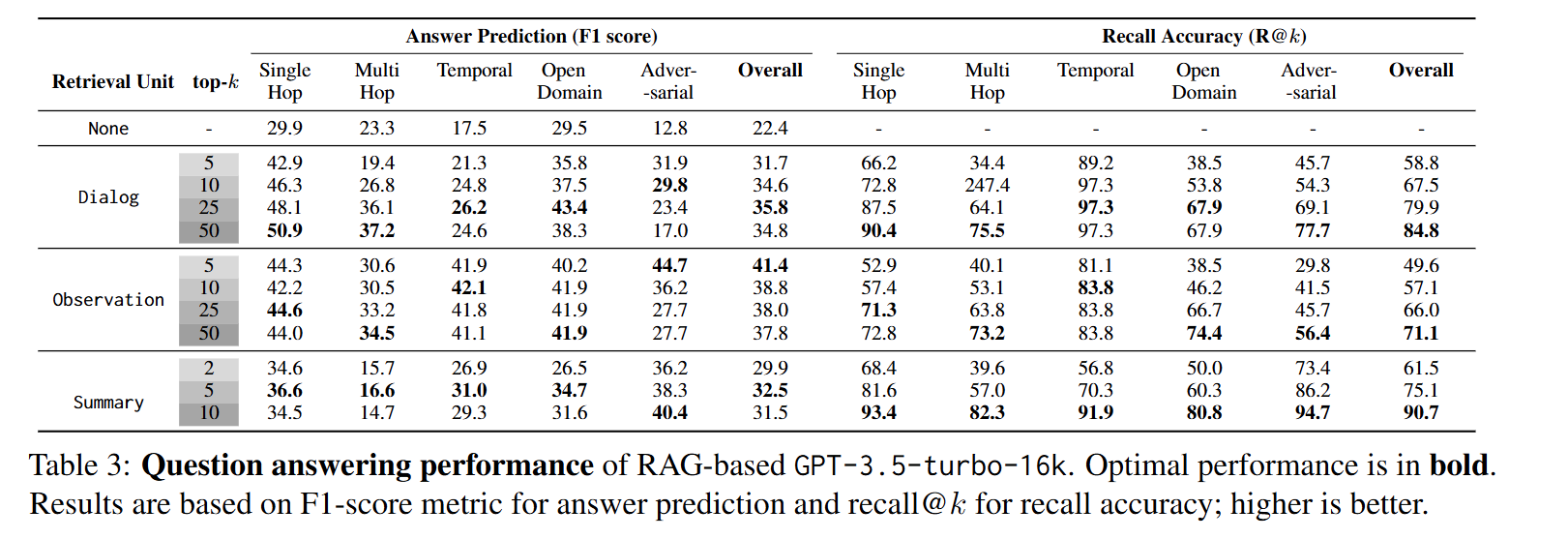
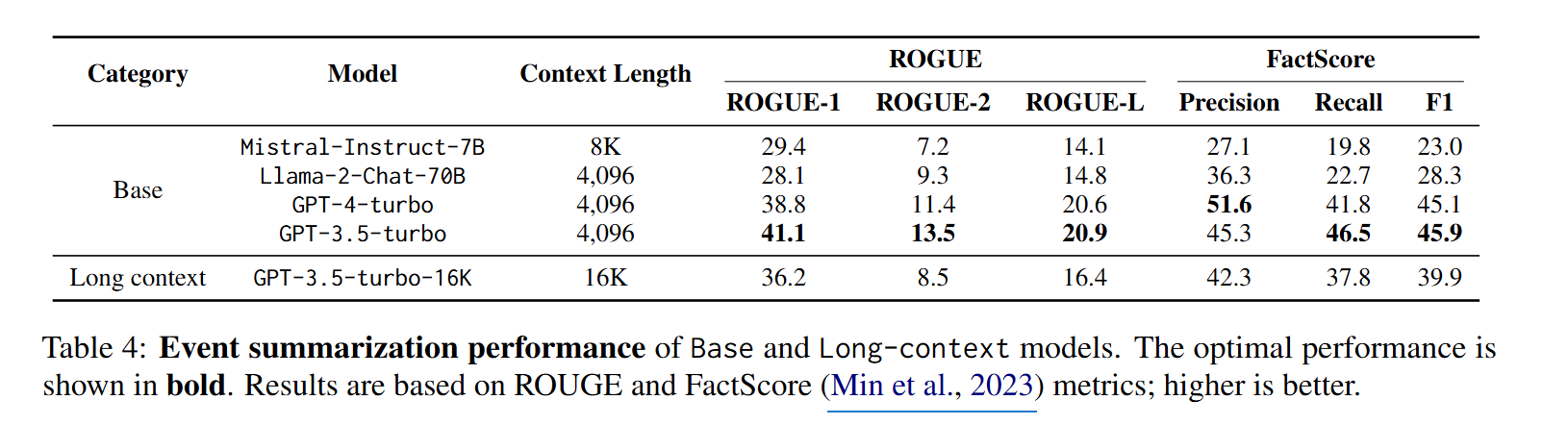
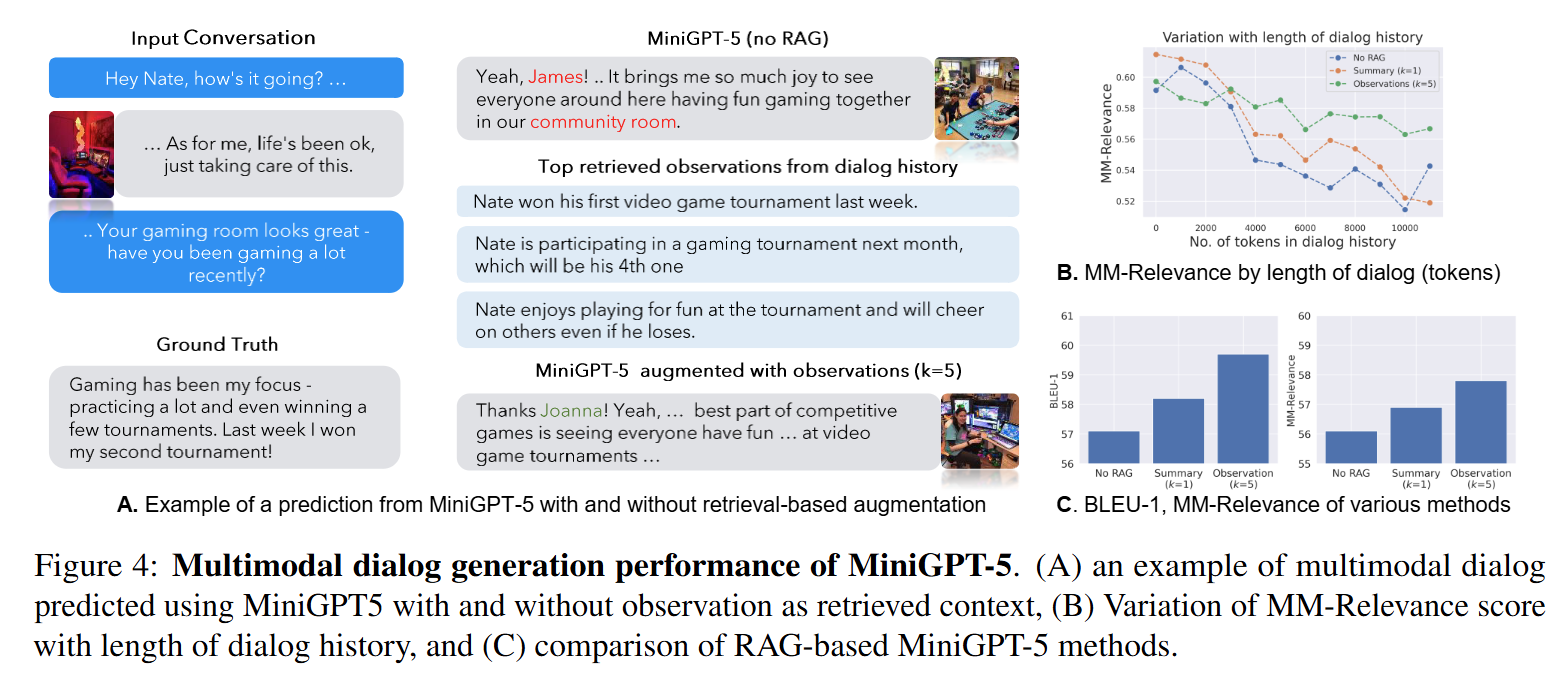
결과를 요약하면 아래와 같습니다.
Question Answering Task
- 모델의 제한된 context 길이는 긴 대화를 이해하는데 한계점으로 작용
- Long Context LLMs는 긴 Context를 잘 이해하나, 쉽게 잘못된 정보를 생성할 수 있음
- RAG 관련
- 대화가 Observation으로 저장될 때 RAG가 효과적이었음
- Session Summarization을 Context로 사용하면 정보 손실로 인해 성능이 크게 개선되지 않음
- LLMs는 대화 안에서 시간 개념을 이해하는데 어려움을 겪음
Event Summarization Task
- QA Task와 마찬가지로 대부분의 모델이 Long Context를 잘 활용하지 못함
- 아래와 같은 오류들이 발생하였음
- 정보 누락: 모델이 긴 대화에서 시간적/인과적 연결을 이해하지 못함
- 허위 정보: 대화에서 존재하지 않거나 다른 사건의 일부인 추가 세부 정보를 생성함
- 대화 신호 오해: 풍자나 유머와 같은 대화 신호를 이해하지 못함
- 잘못된 화자 귀속: 말하는 사람의 의도와 다르게 해석함
- 무의미한 대화: 무의미한 대화를 중요 사건으로 인식함
Conclusion
매우 긴 대화 속에서 LLM의 기억 및 대화 생성 능력을 평가할 수 있는 데이터셋인 LOCOMO를 살펴보았습니다. 해당 데이터셋을 통해 아직 상당수의 LLMs가 긴 대화 맥락을 처리하고 이해하는데 어려움을 겪고 있는 것을 알 수 있었습니다.
연구팀이 꼽은 본 연구의 한계점은 아래와 같습니다.
- Hybrid human-machine generated data: 실제 대화에서 수집한 데이터셋이 아니기 떄문에 실제 대화의 뉘앙스를 반영하지 못했을 수도 있음
- Limited expolaration of multimodal behavior: 데이터셋의 이미지들은 웹에서 수집되어 personal image에서 나타나는 일관성이 없을 수 있음
- Language: 데이터셋이 영어로만 구성됨
- Closed-source LLMs: 데이터셋 생성을 위해 Closed-source LLMs만을 사용하였음
- Evaluation of long-form NLG: LLMs가 과도하게 장황한 답변을 생성하는 경향이 있어, 답변의 정확성을 평가하는데 어려움이 있었음
감사합니다 😊
![[번역] The Second Half](https://images.unsplash.com/photo-1760592150404-adacb88548e2?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDJ8fHx8fHx8fDE3NjA2NTUzOTJ8&ixlib=rb-4.1.0&q=80&w=600)
![[논문 리뷰] ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS](https://images.unsplash.com/photo-1499428665502-503f6c608263?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDcyfHx8fHx8fHwxNzUyNDgwODc3fA&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 5편 (완)](https://images.unsplash.com/photo-1749225595496-06cd2c49fa2b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDZ8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 4편](https://images.unsplash.com/photo-1749221836725-494abefcd2a0?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDd8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)