[논문 리뷰] Learning Retrieval Augmentation for Personalized Dialogue Generation
![[논문 리뷰] Learning Retrieval Augmentation for Personalized Dialogue Generation](https://images.unsplash.com/photo-1724525647096-116d4bacbd5f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDV8fHx8fHwyfHwxNzI1MzY2NTM0fA&ixlib=rb-4.0.3&q=80&w=1200)
이번 시간에는 Personalized dialogue generation을 RAG와 결합하여 시도한 "Learning Retrieval Augmentation for Personalized Dialogue Generation" 논문을 살펴봅니다. 특히 최근에 개인화된 AI가 주목 받고 있는데요, AI가 사용자의 페르소나, 정보, 성격 등을 반영한다면 더욱 풍성하고 도움이 되는 답변을 생성할 수 있습니다. 이를 Personalized dialogue generation이라고 하는데요. 연구팀은 어떻게 해당 문제를 풀 수 있었을까요?
논문은 아래 링크에서 확인할 수 있습니다!

1 Abstract
- 기존의 personalized dialogue dataset은 persona profile이 4~5 문장으로 구성되어 있음
- 이는 개인에 대한 충분한 설명을 제공하기 어려움
- 연구팀은 LAPDOG(Learning Retrieval Augmentation for Personalized DialOgue Generation) 모델을 제안
- Story Retriever과 Generator 도입
- Story Retriever는 주어진 Persona profile을 Query로 사용하여, Story 문서에서 관련 정보를 검색
- Generator는 검색한 정보를 활용해 개인화 된 응답을 생성
- Story Retriever와 Generator는 학습을 함께 진행 (joint training framework)
- Story Retriever과 Generator 도입
- CONVAI2 데이터셋과 ROCStory를 보조로 사용한 실험에서 LAPDOG이 기존 방법보다 뛰어난 성능을 보임
2 Introduction
Q. 어떤 문제를 풀고자 했나요?
Personalized dialogue generation은 대화 맥락과 주어진 Persona profile을 기반으로 일관된 응답을 생성하도록 하는 기술입니다.
여기서 Persona Profile은 Agent를 설명하는 배경 문장을 의미합니다. 예를 들어 “나는 사냥을 좋아합니다.”와 같은 문장이 될 수 있습니다.
위와 같은 Persona profile이 주어지면 Agent는 보다 사냥에 초점을 맞춰 대화를 이끌어 나가 사용자 경험을 향상 시킬 수 있습니다.
하지만 기존에는 Persona Profile이 4~5 문장으로 구성되어 Agent의 Persona를 충분히 설명하지 못했다고 합니다. 따라서 연구팀은 Retriever를 활용하여 Persona Profile을 보강하는 다양한 생활 사건, 성격 특성, 동기 및 경험을 포함한 세부 Story 정보를 함께 제공하는 방법을 제안합니다. 이를 통해 답변에서 더 상세하고 현실적인 페르소나를 반영할 수 있었다고 합니다.
Q. 위 문제를 풀기 위해서는 어떤 챌린지들이 있나요?
연구팀은 위 문제를 풀기 위해 아래와 같은 챌린지들을 제시하였습니다.
- retrieval을 위한 명시적 주석의 부족
- Persona profile을 보강하기 위해 어떤 컨텐츠를 선택할 것인가?
- 가져온 컨텐츠의 효과를 어떻게 평가할 것인가?
- Dense Retrieval을 어떻게 학습시킬 것인가?
- Dense Retrieval은 모든 쿼리에 대해 유사한 구절을 일관적으로 선택하는 경향이 있음
- 이 점이 Persona Profile을 풍부하게 보강 하는 것에 방해가 될 수 있음
Q. 연구팀은 어떻게 챌린지를 극복했나요?
이를 극복하고자 연구팀은 LAPDOG(Learning Retrieval Augmentation for Personalized DialOgue Generation) 프레임워크를 제안합니다.
프레임워크의 특징은 다음과 같습니다.
- Story Retrieval과 Generator로 구성됨
- Non-differentiable metrics의 사용
- BLEU, F1, ROUGE-L과 같은 Metric을 사용하여 Retrieval의 훈련을 유도
- 이를 통해 관련 있고 다양한 개인화된 응답을 생성할 수 있다고 함
- 다양성 보장
- Training 단계에서 retrieval candidate augmentation을 수행하여 Retriever가 모든 쿼리에 대해 유사한 구절을 일관되게 선택하는 것을 방지함
- 이를 통해 Generator에 더욱 다양한 Context 입력을 제공할 수 있도록 함
3 Methodology
3.1 Task Formulation
해당 연구에서 풀고자 하는 Task는 persona-based conversation입니다.
Task는 다음과 같이 구성되어 있습니다.
- 페르소나(P): 기계 대화자(m)의 배경 정보를 제공하는 4~5개의 프로필 문장으로 구성
- 대화 문맥(U): 인간 대화자(h)와 기계 대화자(m) 간의 발화를 포함
- 목표: 주어진 페르소나(P)와 대화 문맥(U)을 기반으로 기계 대화자(m)의 응답 r을 생성하는 것
여기서 연구팀이 풀고자하는 챌린지는 페르소나(P)가 대부분 짧기 때문에, 이를 보완하기 위해 Story Dataset (Ex. ROCStroy)에서 Story를 가져와 페르소나(P)를 풍부하게 만들어야 합니다. 더불어 Dataset D와 P 사이의 명시적인 주석 또한 없기 때문에 검색된 컨텐츠의 유용성을 평가할 수 있는 방법이 필요하다고 합니다.
3.2 Training Process
학습은 두 단계로 구성됩니다.
- Supervised training for Generator
- Tune the retriever and learn the retrieval augmentation jointly
사실 기존 RAG의 접근 방식처럼 간단하게 Generator의 확률 분포를 이용하여 Generator와 Retrieval을 한번에 훈련시킬 수 있습니다. 하지만 이 경우에는 Retriever가 고정된 후보 집합에 갇히게 되고 예측된 확률 분포가 Personalized dialogue generation의 목표와 항상 일치하지 않기 때문에 효과적이지 않아 학습을 두 단계로 구성하였다고 합니다.
그럼 각 학습 단계를 살펴보겠습니다!
3.3.1 Supervied Training
$$L_{NLL} = - \log (G_{\theta}(r | P, U)) = - \sum_{i=1}^{|r|} \log (G_{\theta}(r_t | P, U, r_{<t}))$$
- \(r_t\) 는 응답 \(r \) 의 \(t \) 번째 토큰
- \(r_{<t}\)는 응답 \(r\)에서 첫 번째부터 \((t-1)\)번째 토큰까지의 시퀀스
- \(G_{\theta}(\cdot)\)는 generator의 예측 확률 분포를 나타내며, \(\theta \)는 generator의 파라미터
우선 페르소나 ( P )와 대화 맥락 ( U )를 입력으로 받고, 실제 응답 ( r )을 목표로 하는 Generator를 훈련합니다.
이때 별도의 검색 컨텐츠를 포함하지 않으며, NLL을 최소화 하는 것을 목표로 합니다. 이를 통해 Supervied 된 \(Generator G_{sup}\)을 얻을 수 있습니다.
3.3.2 Learning Retrieval Augmentation
Retrieval Augmentation을 학습시키기 위해 연구팀은 앞서 학습한 $G_{sup}$를 활용하였습니다.
\(G_{sup}\)가 검색된 Story \(( d_i \in D_q )\)가 주어진 metric 측면에서 성능을 향상시키는데 유용하다고 판단하면, retriever가 \(d_i\)의 점수를 더 높게 평가하도록 유도하는 방식입니다.
하지만 generation 및 metric 계산 과정 자체가 미분 가능하지 않을 수 있어, 경사하강법을 적용하는데 어려움이 있었다고 합니다.
따라서 Metric 값을 확률 분포로 변환을 수행하였습니다.
$$p_i = \frac{\exp \left( \frac{1}{\tau_g} M(y, \text{Gen}(G_{sup}, (d_i, P, U)) \right)}{\sum_{c=1}^{K} \exp \left( \frac{1}{\tau_g} M(y, \text{Gen}(G_{sup}, (d_c, P, U)) \right)}$$
여기서 메트릭 함수 \(( M(\cdot, \cdot) )\)의 값이 높을수록 성능이 더 좋음을 나타낸다고 합니다. 그리고 유용한 \(d_i\) 는 큰 \(p_i\)를 가지므로, \(p_i\)를 retriever의 학습을 안내하는 감독 신호로 사용할 수 있다고 합니다.
그리고 위에서 구한 metrtic을 바탕으로 retriever가 반환한 유사도 점수를 \(P_R = {p_i}_{i=1}^{K}\)에 가깝게 만들어야 합니다. 이를 위해 쿼리 \(q\)에 대해 상위 K개의 검색된 이야기 \(D_q\)와 그 검색 점수 \(S_q \in \mathbb{R}^K\)가 주어졌을 때, \(S_q \)와 \(P_R\) 간의 KL 발산을 최소화하는 방식을 사용하였습니다.
$$L_R = KL(P_R, \sigma(S_q / \tau_s))$$
이를 통해 RAG와 결합하여 Retrieval을 업데이트할 수 있습니다.
3.3.3 Retrieval Candidate Augmentation
Training process에서 Retriever이 local minimum에 빠져 고정된 후보 집합이나 좁은 범위의 후보만을 일관되게 검색하는 문제가 발생할 수 있습니다.
이를 해결하기 위해 Retrieval Candidate Augmentation을 도입하였습니다.
이는 무작위로 샘플링된 Story를 포함시켜 프레임워크가 더 넓은 범위의 후보를 탐색하도록 유도하는 방법입니다. 다음과 같이 동작합니다.
- 무작위 후보 대체
- 각 \(d_i \)를 확률 \(\rho\)로 무작위로 선택된 후보 \(d_{aug_i}\)로 대체
- \(d_{aug_i} = \text{CandAug}(d_i, \rho); \quad d_i \in D_q\)
- 여기서 \(D_q\)는 검색된 Story의 집합을 나타내며, 교란된(perturbed) 집합 \(( D_{aug_q} = {d_{aug_i}}_{i=1}^{K} )\)를 형성
- 유사도 계산
- 쿼리 \(q\)와 각 \(d_{aug_i}\) 간의 dot product similarity를 계산하여 검색 점수 \((S_{aug_q} = {s_{aug_q,i}}{i=1}^{K})\)를 구함
- retrieval augmentation 학습에 적용
- 검색 증강 학습을 \(S_{aug_q}\)에 적용하고, 다음 손실을 최소화하여 리트리버를 업데이트
- \(L_{aug_R} = KL(P_R, \sigma(S_{aug_q} / \tau_s))\)
3.3.4 Training Retrieval-Augmented Generator
더 나아가 retriever가 얻은 검색 Context를 활용하여 응답을 더 정확하게 생성할 수 있도록 Generator를 Supervised Train을 수행할 수 있다고 합니다.
페르소나, 대화 맥락, 검색 콘텐츠가 주어진 상태에서 응답의 negative log-likelihood를 최소화하는 것을 학습 목표로 합니다.
$$L_G = - \log G_{\theta}(r | P, U, D_{aug})= - \sum_{i=1}^{|r|} \log G_{\theta}(r_t | P, U, D_{aug}, r_{<t})$$
3.3.5 Retrieval-Generator Joint Training
최종적으로 Retrieval과 Generator를 공동으로 훈련하여 성능을 더욱 향상 시킬 수 있습니다.
$$L = L_{aug_R} + L_G$$
연구에서는 별도의 가중치 파라미터를 적용하지 않았는데, 추후에 충분히 시도해 볼 수 있다고 합니다!
3.4 Inference Process
지금까지 Training Process를 살펴보았습니다. 학습된 모델은 어떻게 Inference를 수행할까요?
Inference 단계에서는 우선 ROCStory dataset의 Story를 제공된 Persona와 일치하도록 가져와 Fusion-in-Decoder (FiD)라는 기술을 활용하여 대화 맥락에 통합했다고 합니다.
A. FiD는 여러 Input에 대한 Encoder의 output을 concat하여 Decoder에서 한번에 처리할 수 있도록 한 방법입니다! 자세한 내용은 논문을 참고해주세요!
최종적으로 Decoder에서 Auto-regressive 방식으로 응답을 생성합니다.
4 Experiment
실험 구성을 살펴보겠습니다.
- Dataset
- 개인화된 대화 생성 연구에 널리 사용되는 ConvAI2 활용
- 대화 수: 8939개의 훈련 대화와 1000개의 검증 대화를 포함
- 페르소나 설명: 훈련/검증 분할을 위해 각각 1155/100개의 페르소나 설명을 사용
- 프로필 문장: 각 페르소나는 약 5개의 프로필 문장으로 간결하게 묘사
- 대화 참여자: 사전 정의된 페르소나를 기반으로 상호작용 대화를 수행하는 쌍으로 구성
- 개인화된 대화 생성 연구에 널리 사용되는 ConvAI2 활용
- Retrieval Corpus
- 기존 대화의 페르소나를 보완하는 콘텐츠로 ROCStory(Mostafazadeh et al., 2016)를 보조 검색 데이터셋으로 사용
- ROCStory의 서술 스타일을 페르소나 표현과 더 가깝게 맞추기 위해 'he’를 'I’로, 'does’를 'do’로 변환하는 등의 전처리를 수행
- 해당 코퍼스에는 98,161개의 이야기가 있으며, 각 이야기는 5개의 문장으로 구성
- Experimental Settings
- 백본 모델로 T5 시리즈 모델(small, base, XL)을 사용
- Dense Retriver은 Contriever 사용
- Evaluation Metric
- F1, BLEU, ROUGE_L
연구팀은 비교를 위해 다음과 같은 실험군을 선정하였습니다.
- LAPDOG vs. \(T5^{S/B/XL}_{sup}\) 모델
- \(R_{fix}\): 튜닝되지 않은 retriever
- Reinforcement learning tuning (\(T5^{S}_{sup}\)+\(R_{fix}\)+\(RL\)):
- RAG tuning: Generator의 출력 확률을 기반으로 retriever를 업데이트하는 방식
실험 결과는 다음과 같습니다.
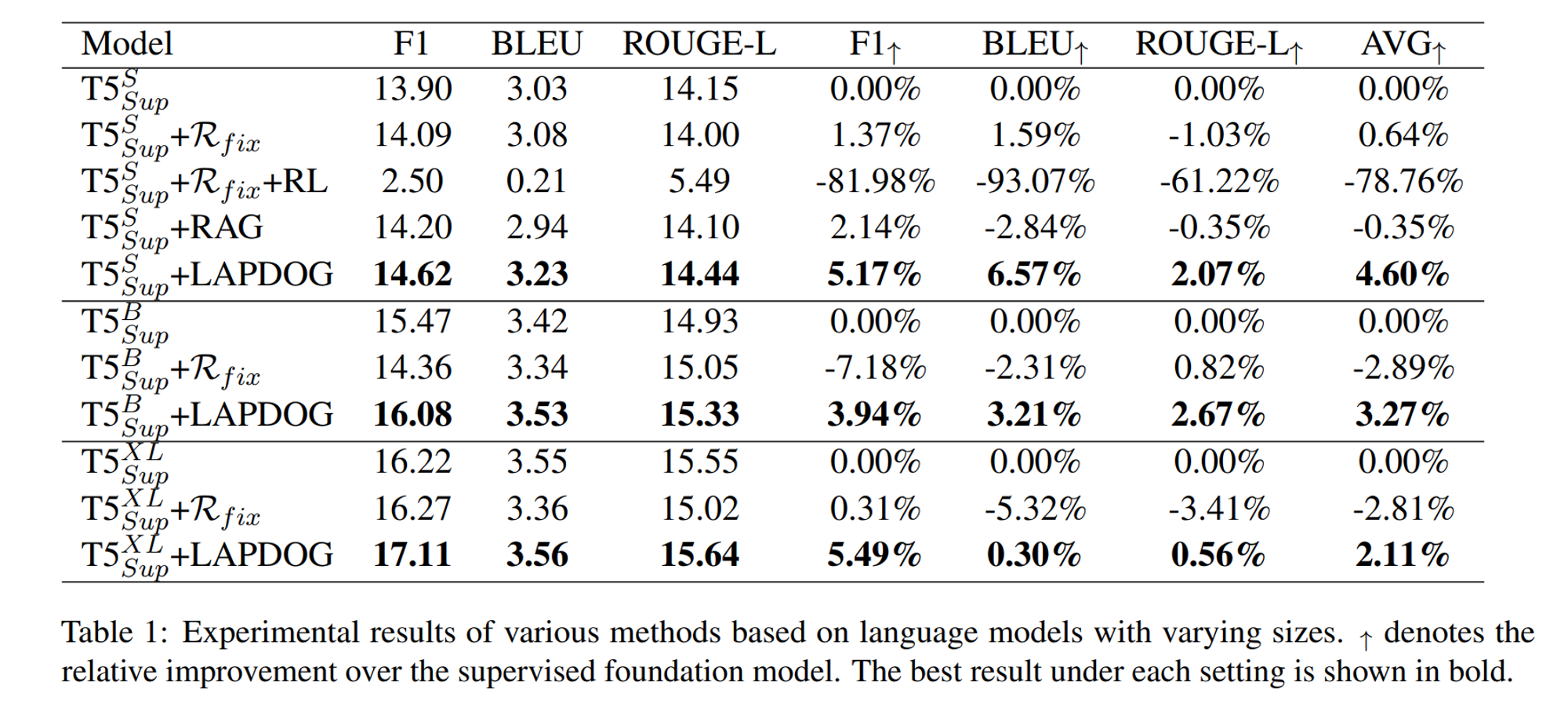
LAPDOG가 더욱 높은 품질의 데이터를 생성하는 것을 볼 수 있습니다.
더불어 백본 모델의 사이즈가 커질수록 일관적으로 성능도 잘 확장되는 것을 보였습니다.
5 Ablation Study
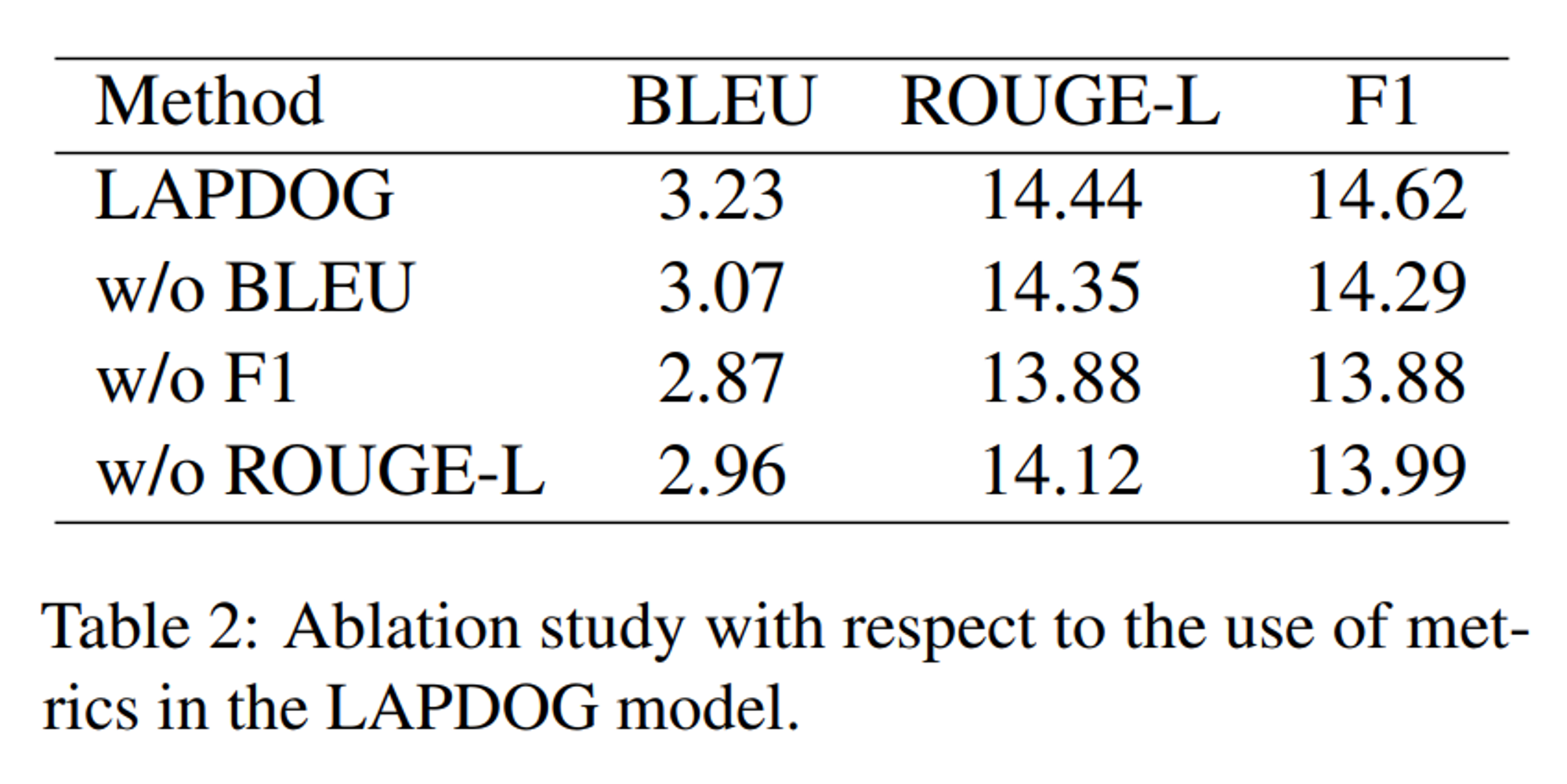
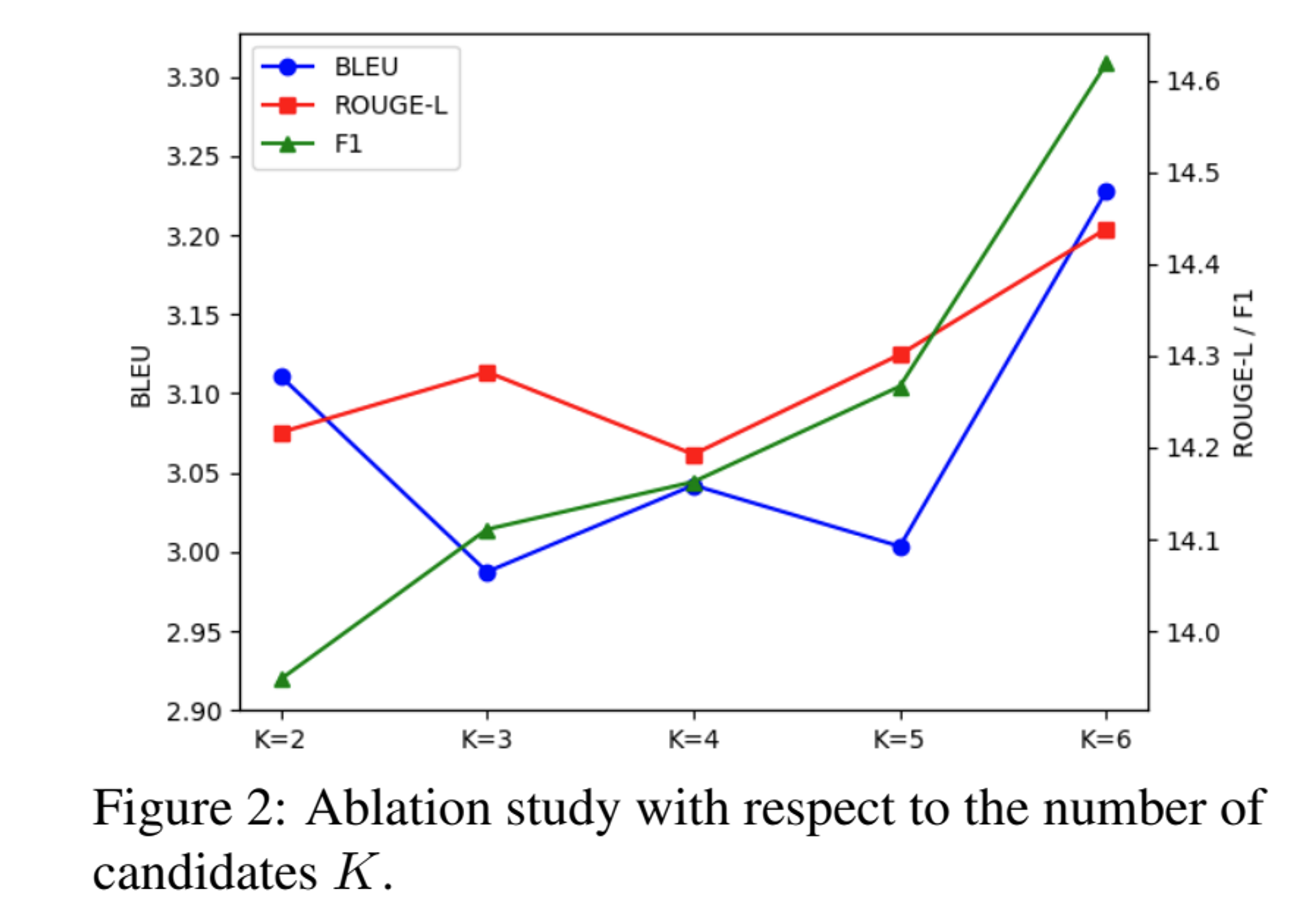
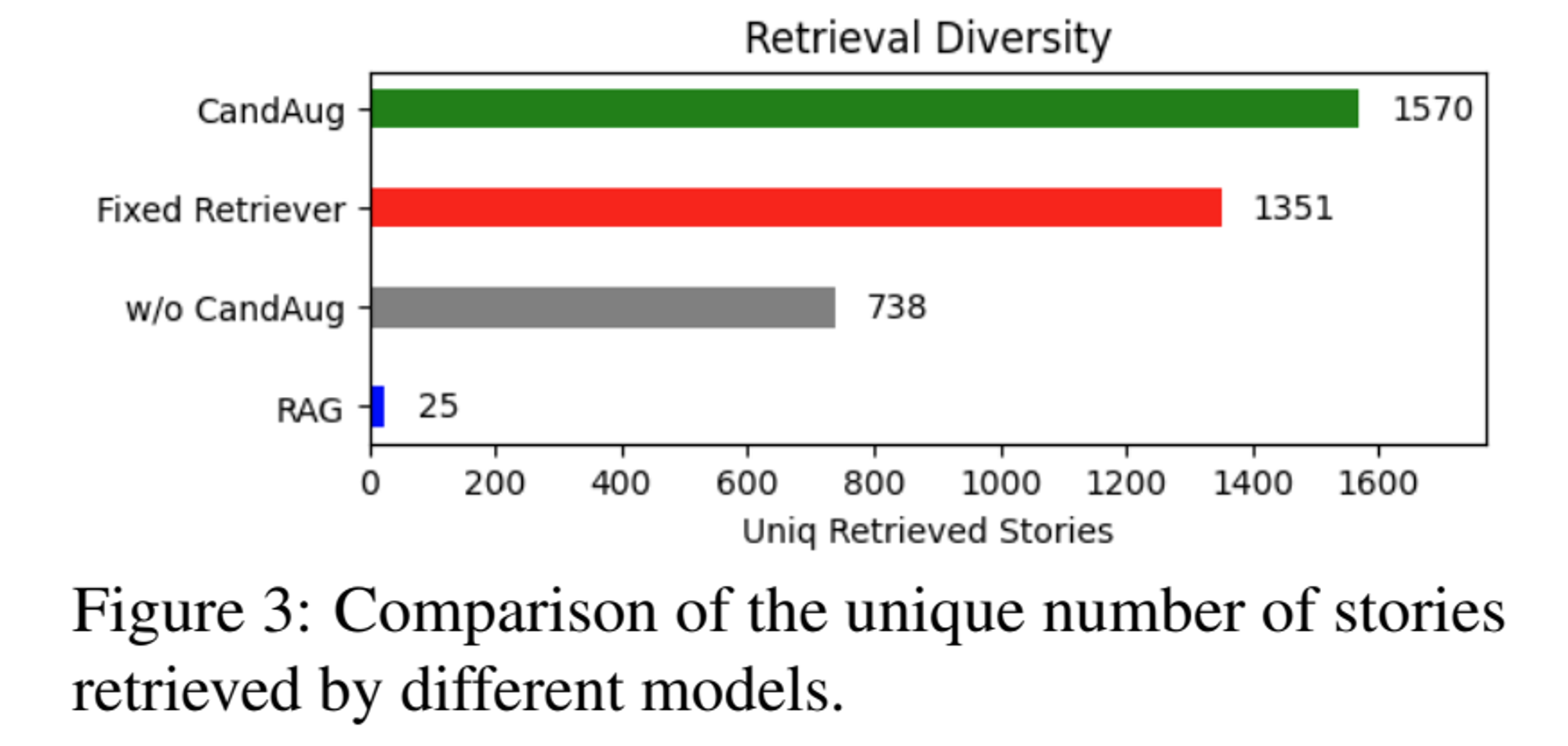
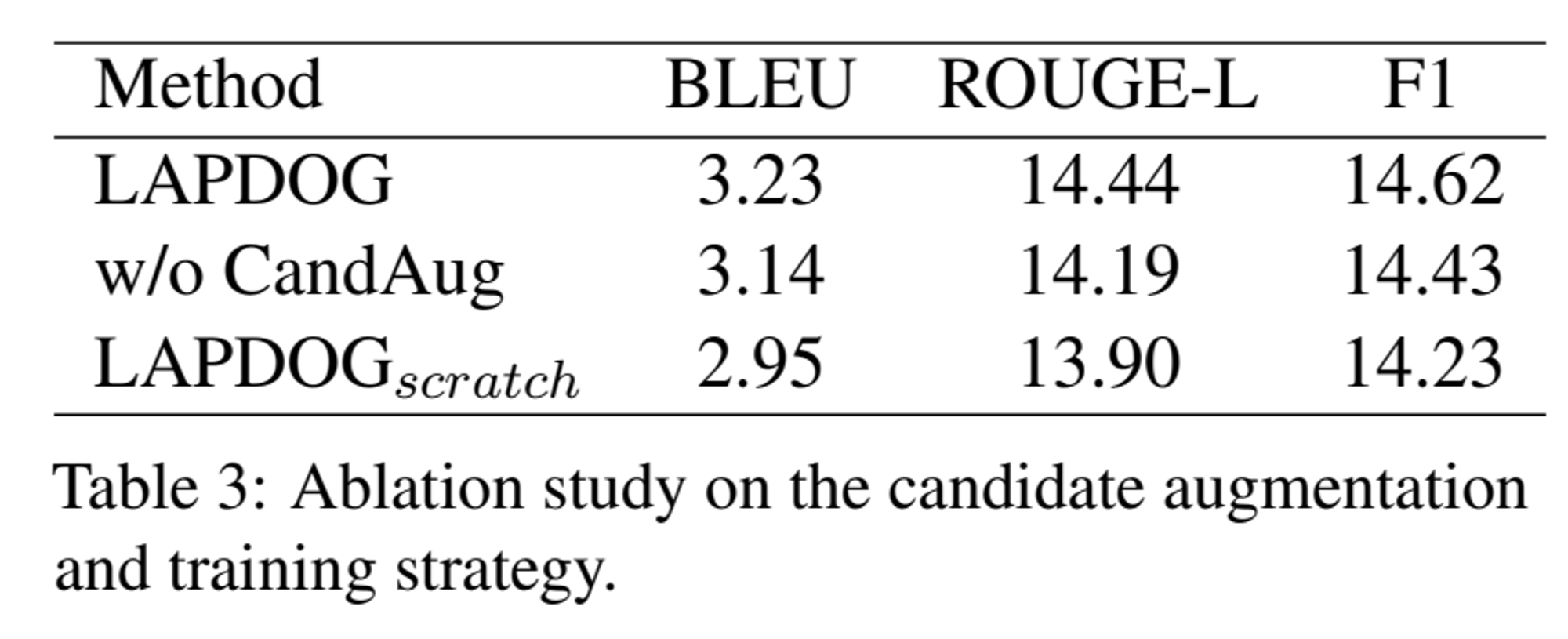
Conclusion & Limitation
이번 시간에는 end-to-end Personalized dialogue generation framework인 LAPDOG 프레임워크에 대해 살펴보았습니다.
LAPDOG은 retriever와 generator를 효과적으로 학습시켜 외부 dataset인 ROCStory에서 persona를 보강하여 성공적으로 성능을 향상시킬 수 있었습니다.
연구팀이 밝힌 limitation은 다음과 같습니다.
- Generator로 LLM의 도입 고려 가능
- 제한된 데이터
- 리소스의 제한으로 제한된 passage 개수 (i.e., 2-6)와 짧은 context length 활용 (i.e., 512 tokens)
- F1, Rouge, BLUE의 합산보다 더 좋은 objective가 있을 수 있음
- Generator로 T5가 아닌 다른 모델을 적용하면 성능 향상을 보일 수 있지 않을까?
감사합니다! 😊
![[번역] The Second Half](https://images.unsplash.com/photo-1760592150404-adacb88548e2?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDJ8fHx8fHx8fDE3NjA2NTUzOTJ8&ixlib=rb-4.1.0&q=80&w=600)
![[논문 리뷰] ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS](https://images.unsplash.com/photo-1499428665502-503f6c608263?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDcyfHx8fHx8fHwxNzUyNDgwODc3fA&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 5편 (완)](https://images.unsplash.com/photo-1749225595496-06cd2c49fa2b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDZ8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 4편](https://images.unsplash.com/photo-1749221836725-494abefcd2a0?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDd8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)