Python Dictionary의 순서 보장

들어가며
Python Dictionary는 key-value pair를 저장하는 유용한 자료구조 입니다. 그런데 Dictionary의 Key 순서는 과연 보장이 될까요? 아래 문제를 한 번 풀어봅시다.
example_dict = {
'a': 1,
'b': 2,
'c': 3
}
if example_dict.keys() == ['a','b','c']:
print('True')
else:
print('False')위 코드의 결과는 무엇일까요?
- True
- False
문제의 정답은 Python 3.6+ 기준으로 True입니다. 즉, Dictionary Key 순서가 보장됩니다. 다시 말하면 3.6 이전에는 순서가 보장되지 않았고, OrderedDict를 사용하여 순서를 보장해야 했습니다. 어떤 변화가 있었길래 순서 보장이 가능해진 것일까요?
Python Dictionary는 어떻게 동작할까?
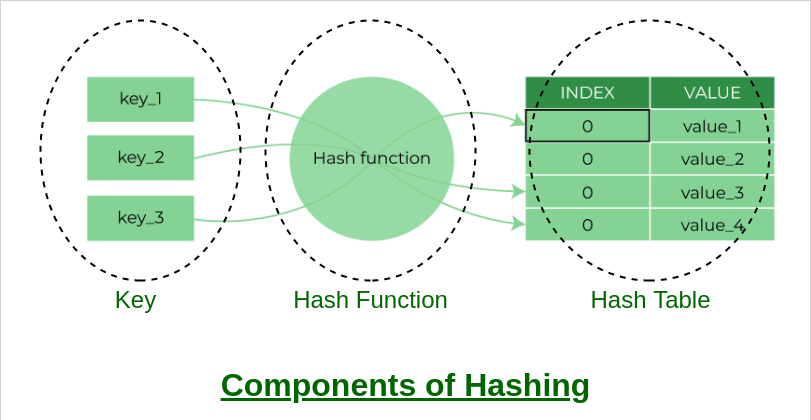
Python Dictionary는 내부적으로 Hash Table을 이용하는 자료구조입니다.
Hash란 임의의 크기를 가진 데이터를 고정된 크기의 값으로 변환하는 함수입니다. Python Dictionary는 Hash 함수를 활용하여 Key를 Hash 값으로 변환한 후, 이를 Index로 변환하여 Value를 특정한 메모리 위치에 저장합니다. 따라서 우리는 Key를 통해 Value에 O(1)으로 접근이 가능한 것이죠.
Hash Collision
본격적으로 Dictionary의 Key 순서 보장 원리를 살펴보기 전에, Hash Collision에 대해 먼저 알아 보겠습니다. Hash Collision이란 Hash Table에서 서로 다른 Key가 같은 Hash 값을 가지는 현상을 의미합니다. Hash Collision을 어떻게 해결하느냐에 따라 Hash Table의 성능을 결정짓는 중요한 요소입니다. 대표적으로는 Chaining 방식과 Open Addressing 방식이 있습니다.
각 방식은 다음과 같아요:
- Chaining
- Hash Table의 각 슬롯을 연결 리스트 (Linked list) 혹은 동적 배열로 만들어 충돌이 발생하면 해당 슬롯의 리스트에 추가하는 방식
- 초기에 해시 테이블의 크기를 크게 만들 필요가 없으며, 동적으로 리스트 크기를 조절할 수 있다는 장점이 있음
- 하지만 연결 리스트를 사용하므로 추가적인 메모리 할당 및 접근 비용과 공간 지역성(Spatial Locality)가 확보 되지 않음
- Open Addressing
- 충돌이 발생하면 테이블의 다른 빈 슬롯을 Probing (탐사)하여 저장하는 방식
- 연속된 메모리 위치를 Probing하여 Spatial Locality를 확보할 수 있음
- 하지만 연속된 키들이 같은 영역에 집중적으로 모이는 Clustering 현상이 발생하여 성능 저하가 일어날 수 있으며, Hash Table의 크기를 동적으로 조절하기 어려움
Python에서는 Open Addressing 방식을 채택하여 Hash Table을 관리합니다. 즉 Collision이 발생하면 Probing을 통해 Hash Table 내에 다른 인덱스를 찾아서 관리하게 됩니다.
Compact Dictionary의 등장 (Python 3.6+)


하지만 앞서 살펴보았듯, Open Addressing 방식은 Probing을 위해서는 미리 빈 슬롯 공간을 가지는 Hash Table이 필요하였고, 이는 메모리 낭비로 이어졌죠. 따라서 메모리 낭비를 방지하고자 Compact Dictionary 구조가 새로 도입이 됩니다.
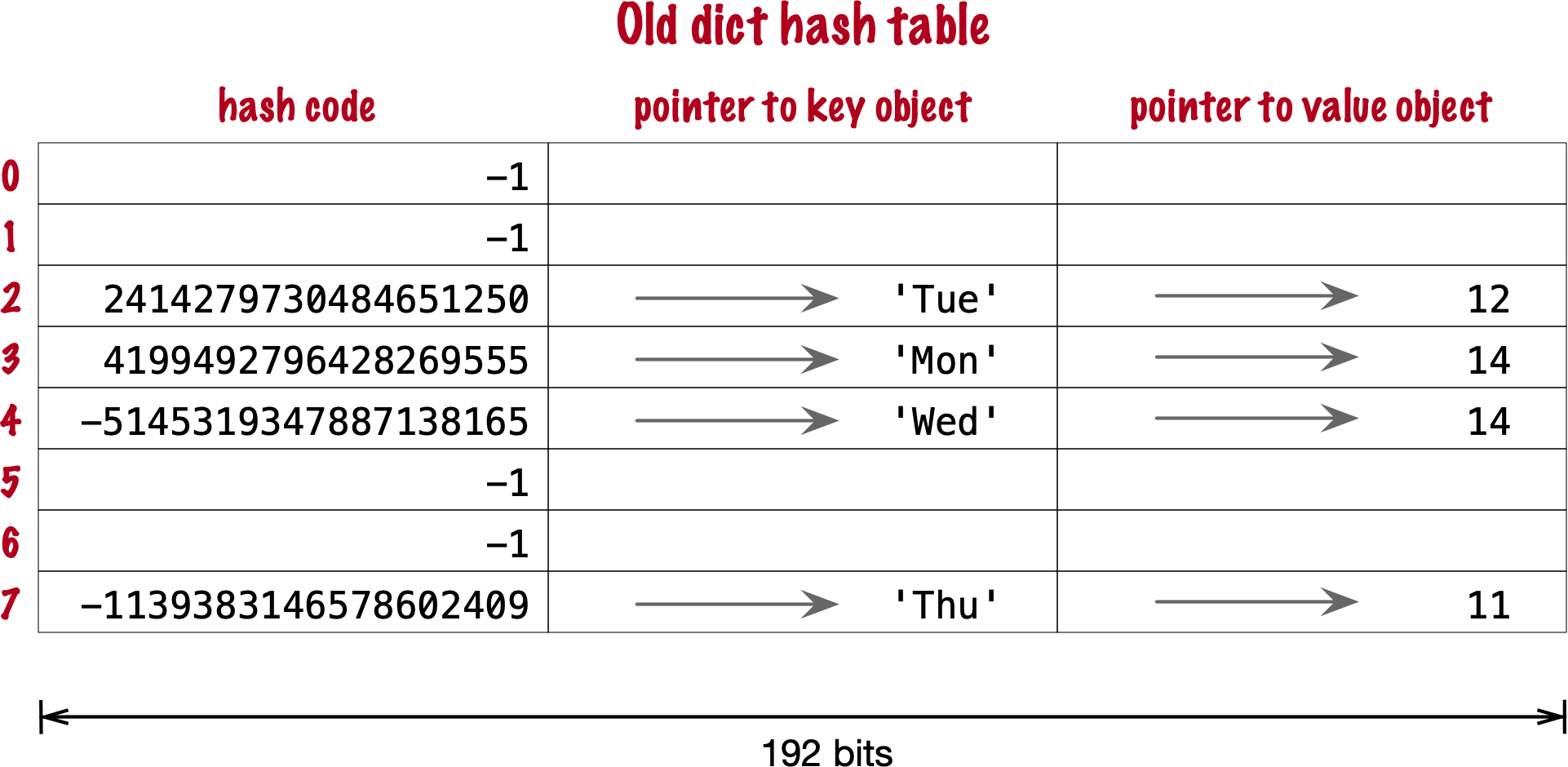
기존에는 Hash Table이 아래 3가지 필드로 구성되었습니다.
- Hash Code: Key의 해시 값
- Pointer to key object: Key Object의 포인터 값
- Pointer to value object: Value Object의 포인터 값
예를 들어 한 필드가 8바이트라고 가정하면, 8개의 버킷이 있는 딕셔너리는 8 * 3 * 8로 192 바이트의 해시 테이블이 필요합니다. 심지어 key-value는 절반인 4개 밖에 사용하지 않는데 말이죠.
위와 같은 문제를 피하고자, Compact Dictionary에서는 Entries와 Indices라는 두 개의 배열로 나누어 Hash Table을 관리합니다.
각 배열의 역할은 다음과 같습니다:
Entries
- Key-Value Pair를 저장하는 연속적인 배열
- Hash Code, Key Object Pointer, Value Object Pointer로 구성되어 있음
- 빈 공간 없이 데이터가 연속적으로 채워짐
Indices
- 실제 해시 테이블 역할을 하는 Sparse Array (희소 배열)
- Entries의 Index 값을 저장함
예를 들어 {"Thu": 11}이라는 key-value pair을 Python 딕셔너리에 새로 저장할 때 내부 동작은 다음과 같습니다:
- 키 값(
"Thu")의 해시 코드를 계산하고, 이 해시 코드를indices배열의 크기로 나눈 나머지를 구하여indices배열 내 초기 슬롯 위치를 결정합니다 (예시에서는indices배열의 7번 인덱스). - 만약 결정된 슬롯에 이미 다른 값이 저장되어 있다면(Collision), probing을 통해 빈 슬롯을 찾습니다.
entries배열에 새로운 항목을 추가합니다. 이 항목은"Thu"키에 대한 해시 코드, 키 객체 포인터, 값 객체 포인터(11)로 구성됩니다 (예시에서는entries배열의 3번 인덱스에 저장)."Thu"키에 해당하는indices배열의 슬롯에 새로 추가된entries배열의 인덱스 값(3)을 저장합니다.

Compact Dictionary의 메모리 사용량은 어떨까요?
Entries의 각 필드는 8바이트라 가정하고, Indices는 각 1바이트가 필요하다고 가정해보겠습니다.
- Entries: 4개 항목 * 24바이트 (8바이트 * 3필드) = 96바이트
- Indices: 8개의 1바이트 버킷 = 8바이트
- 96바이트 + 8바이트 = 104바이트
이전 구조는 192 바이트가 필요한데 반해, 개선된 Compact Dictionary 구조에서는 104바이트 정도로 약 46% 정도 메모리 절약 효과가 있습니다.
실제로 Official Python Document에서도 20-25% 정도의 메모리 사용량 절감 효과가 있었다고 합니다.
이러한 구조를 도입하면서 키 값의 순서 보장이 자연스럽게 가능해졌습니다. 기존의 단일 해시 테이블에서는 키의 순서를 보장할 방법이 없었습니다. 그 이유는 해시 함수를 거치면서 인덱스 위치가 완전히 섞이기 때문입니다.
그러나 새로운 구조에서는 entries 배열에 키가 추가된 순서대로 저장되기 때문에, 키를 저장한 순서 그대로 접근하는 것이 가능해졌습니다. 사실 어찌보면 키 순서 보장은 처음부터 의도한 기능이 아니라, 메모리 최적화를 위한 구조 변경의 부산물이었던 것이죠.
마치며

이전 포스트에 이어 이번 시간에도 파이썬의 내부 동작 원리에 대해 살펴보았는데요, 당연하게 사용하는 메서드나 자료구조에도 흥미로운 이야기나 기술들이 많이 담겨있는 것 같아요 😊
다음 시간에는 Python의 최대의 숙적(?)으로 꼽히는 GIL (Global Interpreter Lock)에 대해 살펴보겠습니다.
감사합니다 😊
![[번역] The Second Half](https://images.unsplash.com/photo-1760592150404-adacb88548e2?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDJ8fHx8fHx8fDE3NjA2NTUzOTJ8&ixlib=rb-4.1.0&q=80&w=600)
![[논문 리뷰] ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS](https://images.unsplash.com/photo-1499428665502-503f6c608263?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDcyfHx8fHx8fHwxNzUyNDgwODc3fA&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 5편 (완)](https://images.unsplash.com/photo-1749225595496-06cd2c49fa2b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDZ8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)
![[번역] How to Do Great Work - 4편](https://images.unsplash.com/photo-1749221836725-494abefcd2a0?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDd8fHx8fHx8fDE3NDkzNjExNDB8&ixlib=rb-4.1.0&q=80&w=600)